整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
以深度學習為主的人工智能算法模型在日常AI應用中逐漸占據主流方向,相關的各類產品也是層出不窮。我們平時所看到的AI產品,像刷臉支付、智能語音、銀行的客服機器人等,都是AI算法的具體落地應用。AI技術在具體落地應用方面,和其他軟件技術一樣,也需要具體的部署和實施的。既然要做部署,那就會有不同平臺設備上的各種不同的部署方法和相關的部署架構工具,目前在人工智能的落地部署方面,各大平臺機構也都是大展身手,紛紛推出自家的部署平臺。
目前市場上應用最廣泛的部署工具主要有以下幾種:騰訊公司開發的移動端平臺部署工具——NCNN;Intel公司針對自家設備開開發的部署工具——;NVIDIA公司針對自家GPU開發的部署工具——;Google針對自家硬件設備和深度學習框架開發的部署工具——;由微軟、亞馬遜 、 和 IBM 等公司共同開發的開放神經網絡交換格式——ONNX(Open Neural Network )。除此之外,還有一些深度學習框架有自己的專用部署服務:比如自己提供的部署服務: Serving、 Lite,pytorch自己提供的部署服務:。

本文主要是針對這些不同的部署工具做一個簡單的分析,對比一下各家不同的部署工具到底有哪些優勢和不足之處,方便大家在做部署的時候能夠找到適合自己的項目的部署方法。具體的各種不同的部署工具的下載安裝和使用方法會在后續的文章中做出詳細的教程,關注深度人工智能學院,了解最實用的人工智能干貨知識。
NCNN
NCNN是騰訊優圖實驗室首個開源項目,是一個為手機端極致優化的高性能神經網絡前向計算框架。并在2017年7月正式開源。NCNN做為騰訊優圖最“火”的開源項目之一,是一個為手機端極致優化的高性能神經網絡前向計算框架,在設計之初便將手機端的特殊場景融入核心理念,是業界首個為移動端優化的開源神經網絡推斷庫。能實現無第三方依賴,跨平臺操作,在手機端CPU運算速度在開源框架中處于領先水平。基于該平臺,開發者能夠輕松將深度學習算法移植到手機端,輸出高效的執行,進而產出人工智能APP,將AI技術帶到用戶指尖。
NCNN從設計之初深刻考慮手機端的部署和使用。無第三方依賴,跨平臺,手機端 CPU的速度快于目前所有已知的開源框架。基于 NCNN,開發者能夠將深度學習算法輕松移植到手機端高效執行,開發出人工智能 APP,將 AI 帶到你的指尖。NCNN目前已在騰訊多款應用中使用,如 QQ,Qzone,微信,天天P圖等。
下面是NCNN在各大系統平臺的應用發展狀態情況:
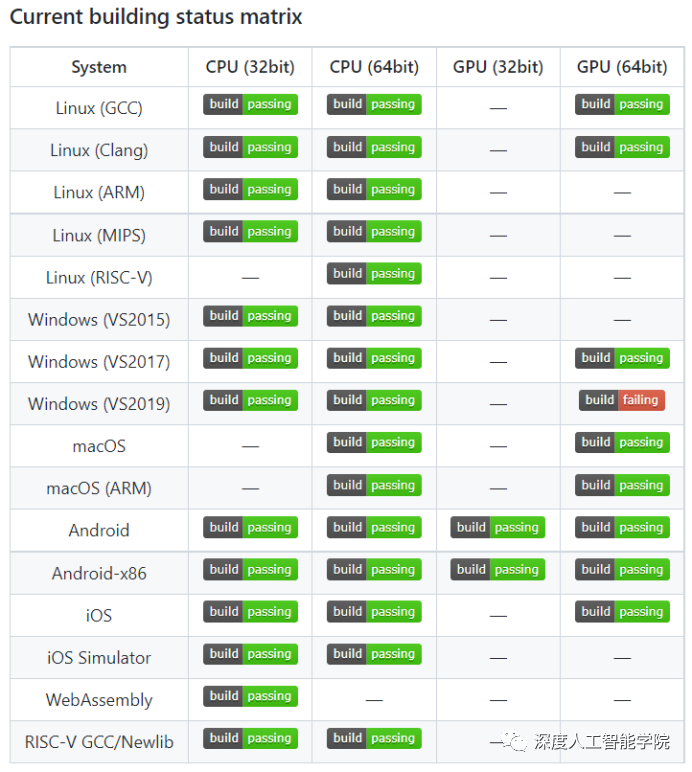
從NCNN的發展矩陣可以看出,NCNN覆蓋了幾乎所有常用的系統平臺,尤其是在移動平臺上的適用性更好,在Linux、Windows和Android、以及iOS、macOS平臺上都可以使用GPU來部署模型。
根據官方的功能描述,NCNN在各方面的性能都比較優良:
l 支持卷積神經網絡,支持多輸入和多分支結構,可計算部分分支
l 無任何第三方庫依賴,不依賴 BLAS/NNPACK 等計算框架
l 純 C++ 實現,跨平臺,支持 android ios 等
l ARM NEON 匯編級良心優化,計算速度極快
l 精細的內存管理和數據結構設計,內存占用極低
l 支持多核并行計算加速,ARM big.LITTLE cpu 調度優化
l 支持基于全新低消耗的 vulkan api GPU 加速
l 整體庫體積小于 700K,并可輕松精簡到小于 300K
l 可擴展的模型設計,支持 8bit 量化 和半精度浮點存儲,可導入 caffe/pytorch/mxnet/onnx/darknet/keras/(mlir) 模型
l 支持直接內存零拷貝引用加載網絡模型
l 可注冊自定義層實現并擴展
l 恩,很強就是了,不怕被塞卷 QvQ
除此之外,NCNN在對各種硬件設備的支持上也非常給力:
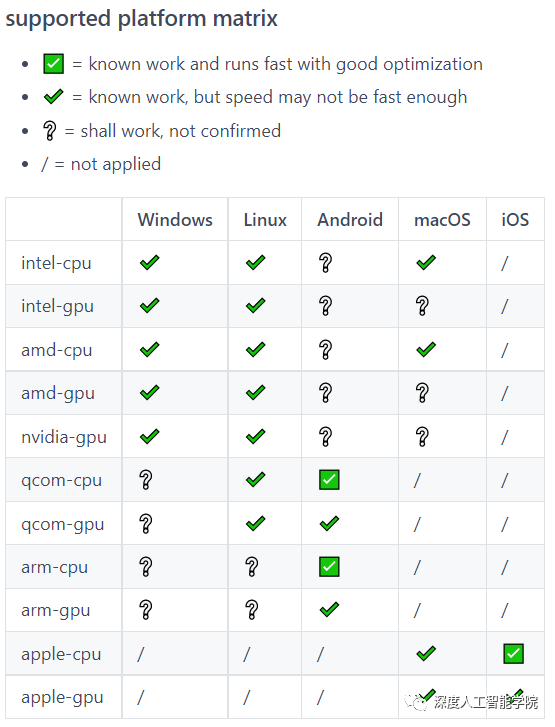
NCNN的官方代碼地址:
移動端的部署工具除了NCNN,還有華盛頓大學的TVM、阿里的MNN、小米的MACE、騰訊優圖基于NCNN開發的TNN等推理部署工具。
工具套件全稱是Open Visual & Neural Network ,是Intel于2018年發布的,開源、商用免費、主要應用于計算機視覺、實現神經網絡模型優化和推理計算()加速的軟件工具套件。由于其商用免費,且可以把深度學習模型部署在英爾特CPU和集成GPU上,大大節約了顯卡費用,所以越來越多的深度學習應用都使用工具套件做深度學習模型部署。
是一個工具集,同時可以兼容各種開源框架訓練好的模型,擁有算法模型上線部署的各種能力,只要掌握了該工具,你可以輕松的將預訓練模型在Intel的CPU上快速部署起來。
對于AI工作負載來說,提供了深度學習推理套件(DLDT),該套件可以將各種開源框架訓練好的模型進行線上部署,除此之外,還包含了圖片處理工具包OpenCV,視頻處理工具包Media SDK,用于處理圖像視頻解碼,前處理和推理結果后處理等。
在做推理的時候,大多數情況需要前處理和后處理,前處理如通道變換,取均值,歸一化,Resize等,后處理是推理后,需要將檢測框等特征疊加至原圖等,都可以使用工具套件里的API接口完成。
目前支持Linux、Windows、macOS、等系統平臺。

工具套件主要包括:Model (模型優化器)——用于優化神經網絡模型的工具, Engine(推理引擎)——用于加速推理計算的軟件包。
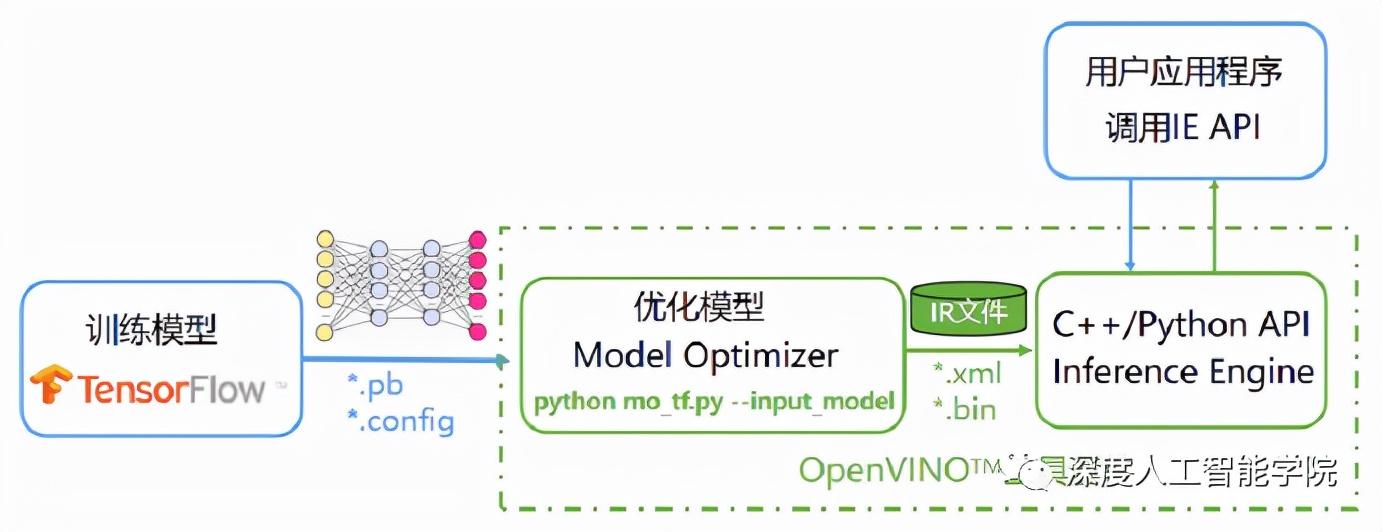
模型優化器是一個python腳本工具,用于將開源框架訓練好的模型轉化為推理引擎可以識別的中間表達,其實就是兩個文件,xml和bin文件,前者是網絡結構的描述,后者是權重文件。模型優化器的作用包括壓縮模型和加速,比如,去掉推理無用的操作(Dropout),層的融合(Conv + BN + Relu),以及內存優化。
推理引擎是一個支持C\C++和python的一套API接口,需要開發人員自己實現推理過程的開發,開發流程其實非常的簡單,核心流程如下:

l 裝載處理器的插件庫
l 讀取網絡結構和權重
l 配置輸入和輸出參數
l 裝載模型
l 創建推理請求
l 準備輸入Data
l 推理
l 結果處理
工具套件的工作流程圖:
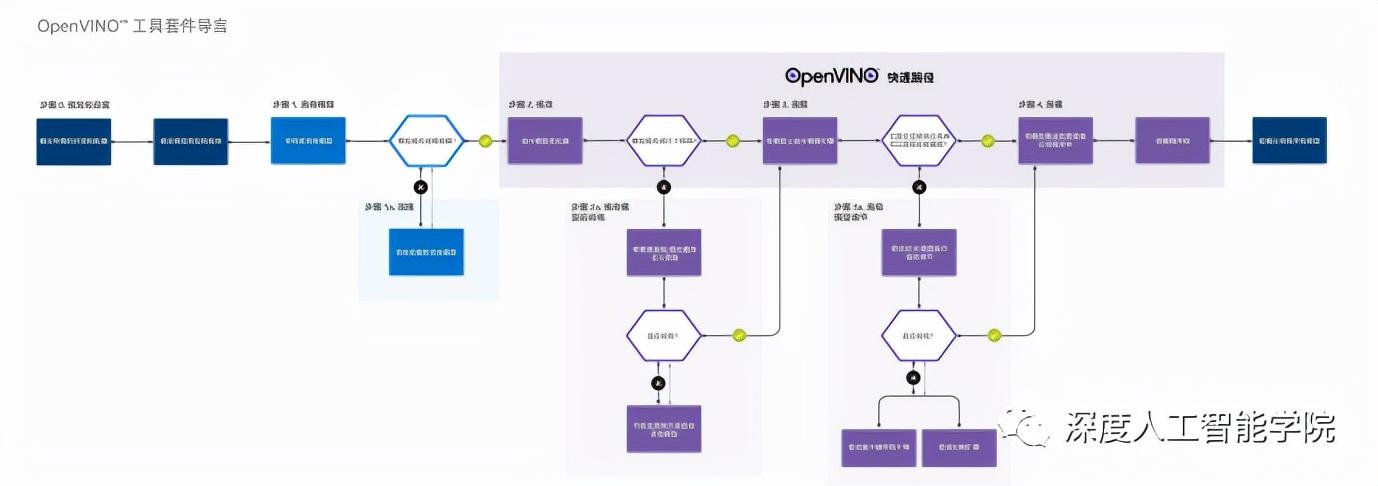
的官方地址:
提醒一下,大家不要去下面這個網站,因為這個網站是一個釀酒廠的網站:
是NVIDIA開發的一個高性能的深度學習推理()優化器,可以為深度學習應用提供低延遲、高吞吐率的部署推理。可用于對超大規模數據中心、嵌入式平臺或自動駕駛平臺進行推理加速。現已能支持、Caffe、Mxnet、Pytorch等幾乎所有的深度學習框架,將和NVIDIA的GPU結合起來,能在幾乎所有的框架中進行快速和高效的部署推理。
是一個C++庫,從 3 開始提供C++ API和Python API,主要用來針對 NVIDIA GPU進行高性能推理()加速,它可為深度學習推理應用提供低延遲和高吞吐量。在推理期間,基于 的應用比僅 CPU 平臺的執行速度快 40 倍。
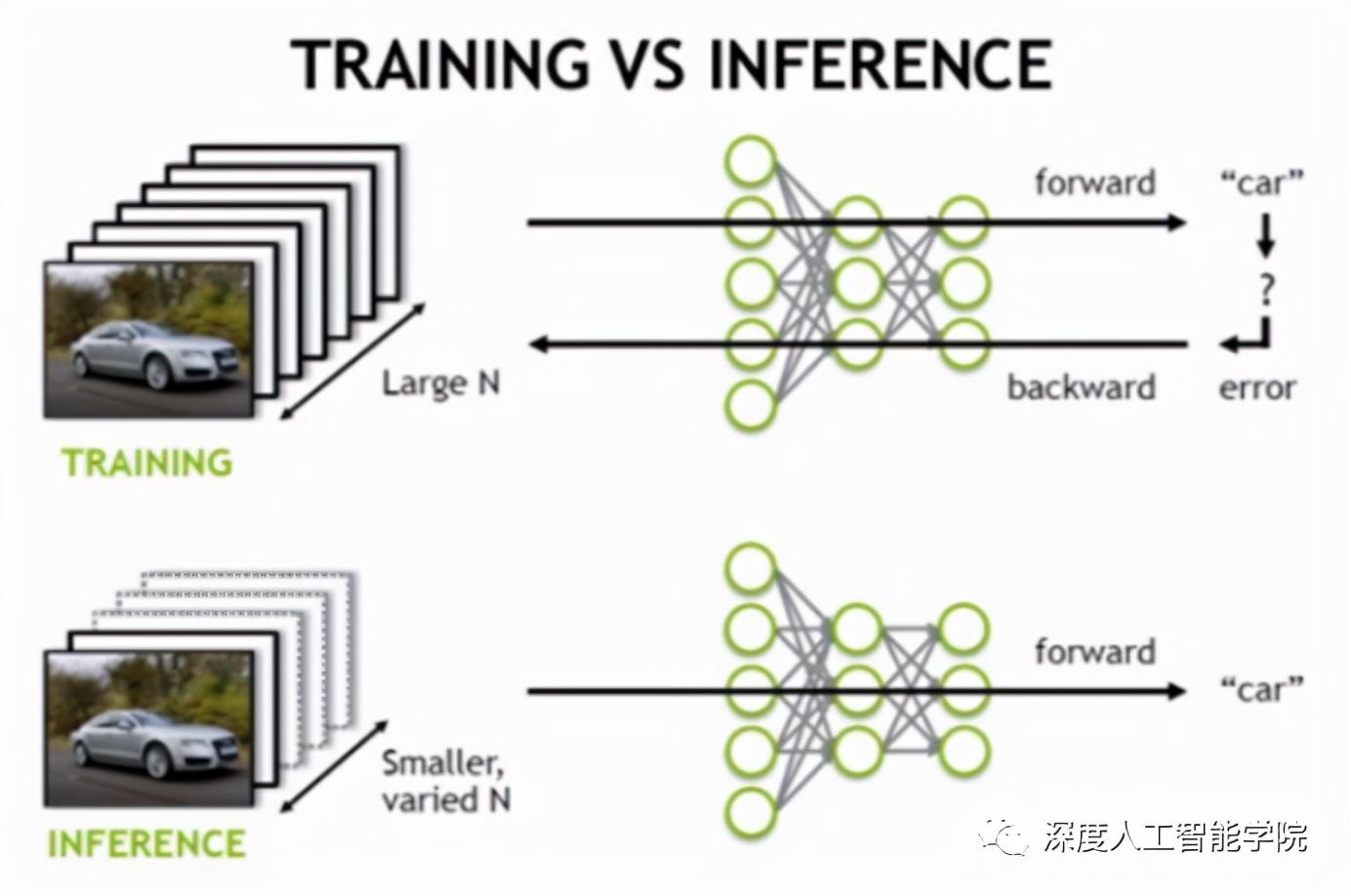
一般的深度學習項目,訓練時為了加快速度,會使用多 GPU 分布式訓練。但在部署推理時,為了降低成本,往往使用單個 GPU 機器甚至嵌入式平臺(比如 NVIDIA Jetson)進行部署,部署端也要有與訓練時相同的深度學習環境,如 caffe, 等。由于訓練的網絡模型可能會很大(比如,,resnet 等),參數很多,而且部署端的機器性能存在差異,就會導致推理速度慢,延遲高。這對于那些高實時性的應用場合是致命的,比如自動駕駛要求實時目標檢測,目標追蹤等。所以為了提高部署推理的速度,出現了很多輕量級神經網絡,比如 ,, 等。基本做法都是基于現有的經典模型提出一種新的模型結構,然后用這些改造過的模型重新訓練,再重新部署。
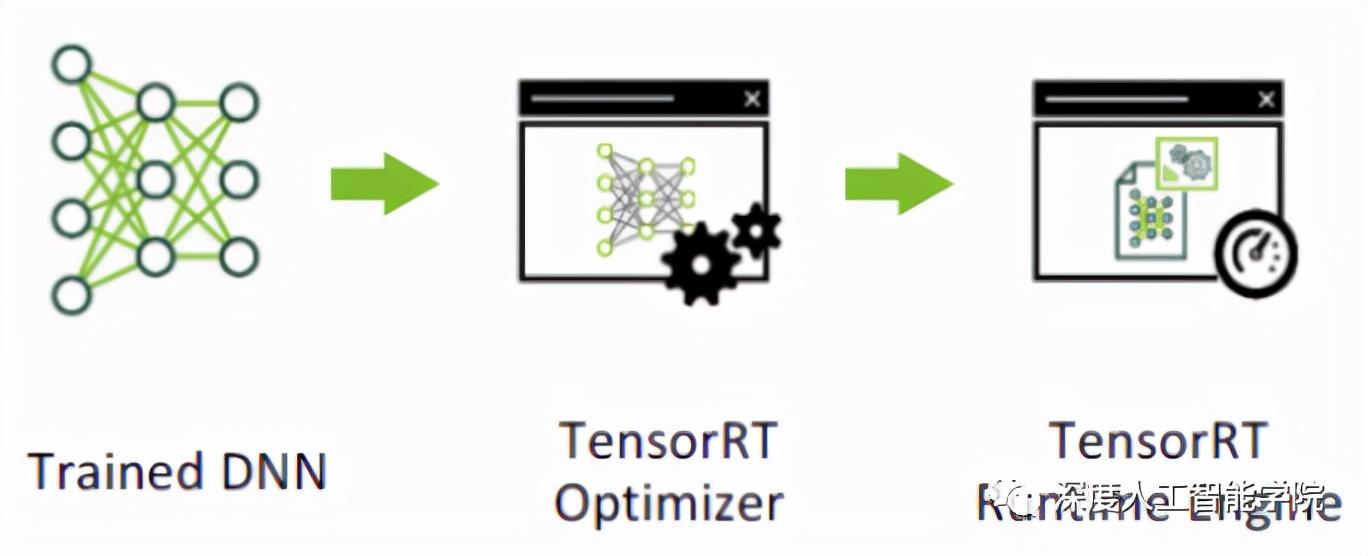
而 則是對訓練好的模型進行優化。 就只是推理優化器。當你的網絡訓練完之后,可以將訓練模型文件直接丟進 中,而不再需要依賴深度學習框架(Caffe, 等)
可以認為 是一個只有前向傳播的深度學習推理框架,這個框架可以將Caffe,,PyTorch 等網絡模型解析,然后與 中對應的層進行一一映射,把其他框架的模型統一全部轉換到 中,然后在 中可以針對 NVIDIA 自家 GPU 實施優化策略,并進行部署加速。
依賴于Nvidia的深度學習硬件環境,可以是GPU也可以是DLA,如果沒有的話則無法使用。支持目前大部分的神經網絡Layer的定義,同時提供了API讓開發者自己實現特殊Layer的操作。
基于 CUDA,NVIDIA 的并行編程模型,能夠利用 CUDA-X AI 中的庫、開發工具和技術,為人工智能、自動機器、高性能計算和圖形優化所有深度學習框架的推理。
的部署分為兩個部分:
1. 優化訓練好的模型并生成計算流圖
2. 使用 Runtime部署計算流圖
的部署流程:
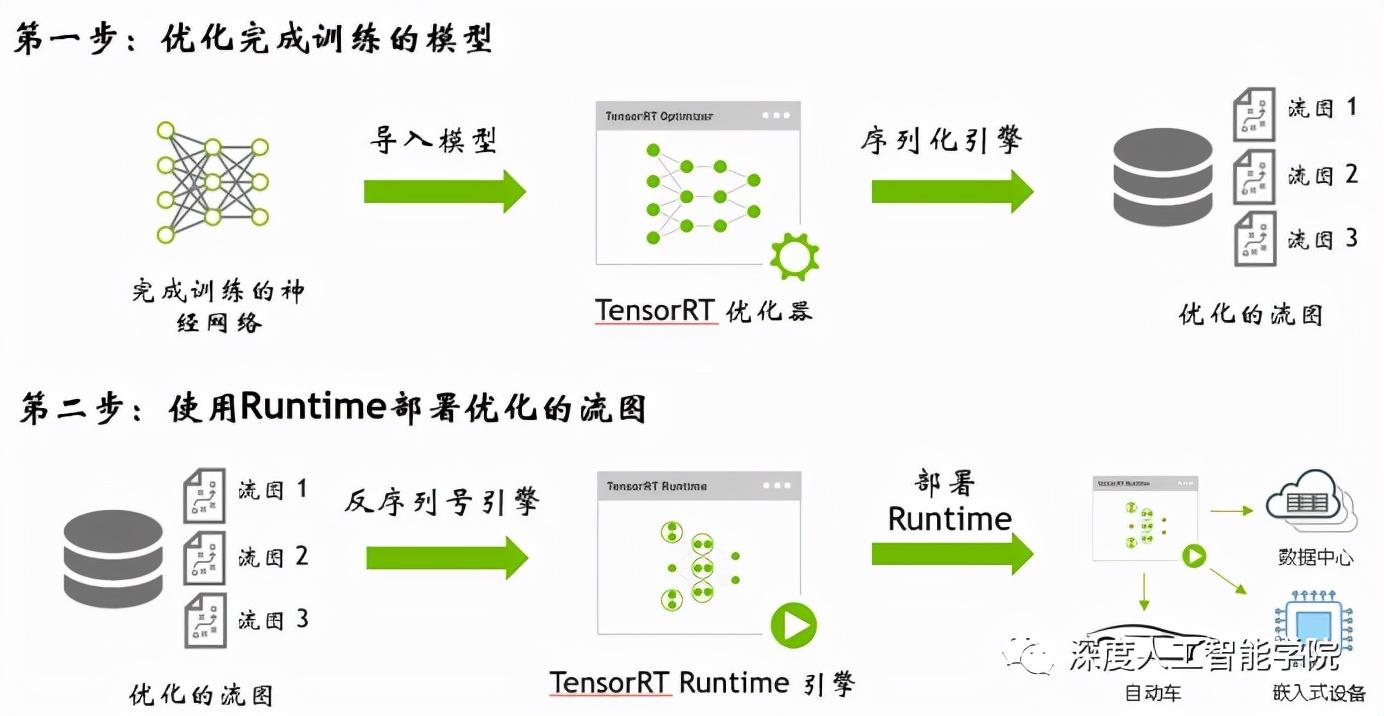
的模型導入流程:
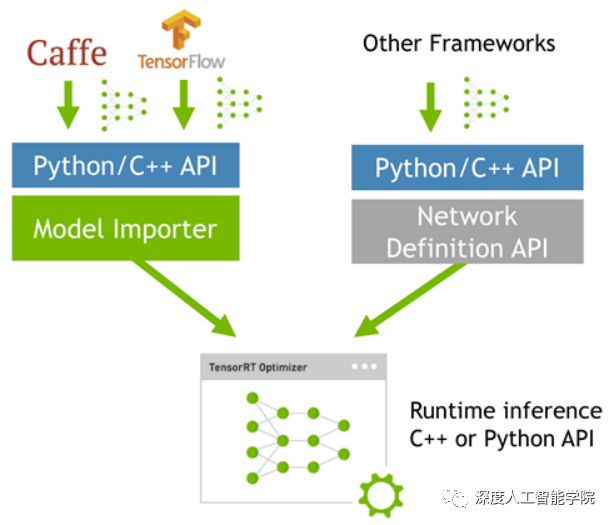
的優化過程:
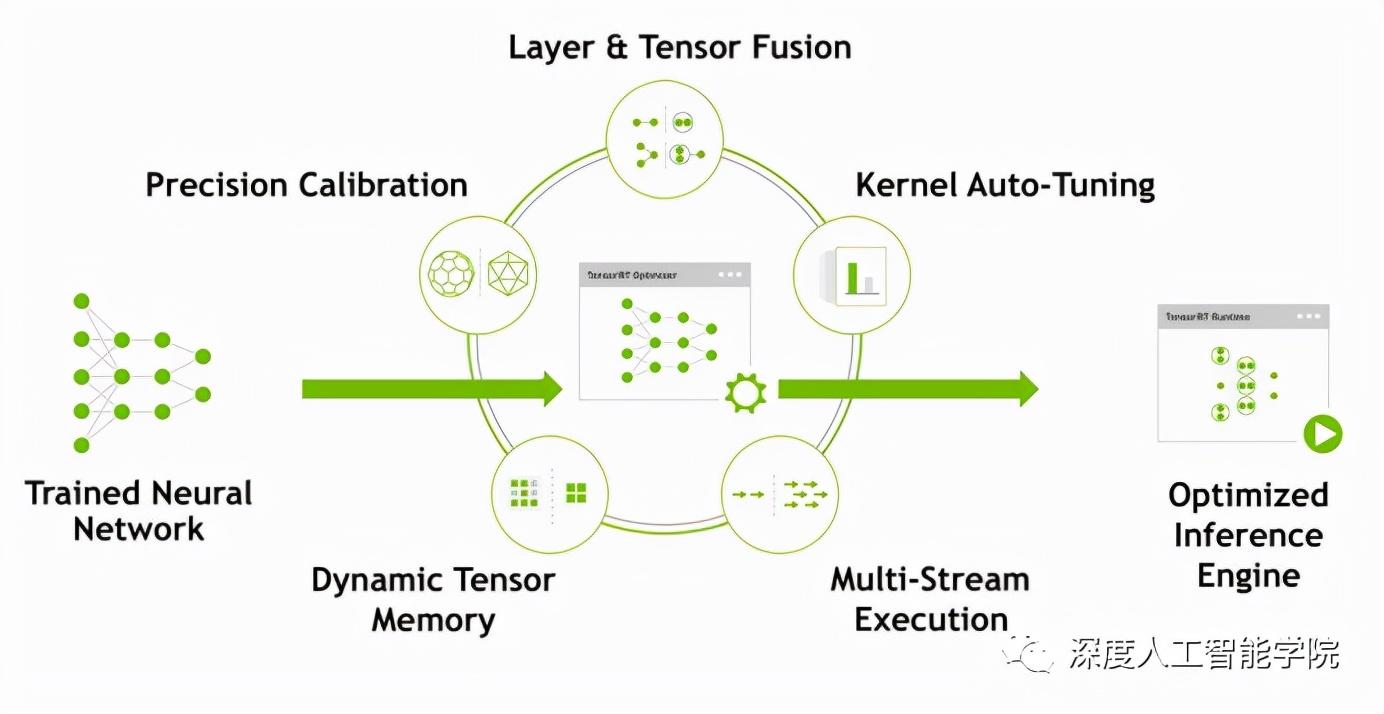
網絡模型在導入至后會進行一系列的優化,主要優化內容如下圖所示
官網下載地址:
開發者指南:
Github地址:
是一款由 Google 開發并開源的多媒體機器學習模型應用框架。在谷歌,一系列重要產品,如 YouTube、Google Lens、ARCore、Google Home 以及 Nest,都已深度整合了 。
是一個基于圖形的跨平臺框架,用于構建多模式(視頻,音頻和傳感器)應用的機器學習管道。 可在移動設備、工作站和服務器上跨平臺運行,并支持移動 GPU 加速。使用 ,可以將應用的機器學習管道構建為模塊化組件的圖形。 不僅可以被部署在服務器端,更可以在多個移動端 (安卓和蘋果 iOS)和嵌入式平臺(Google Coral 和樹莓派)中作為設備端機器學習推理 (On-device Machine )框架。
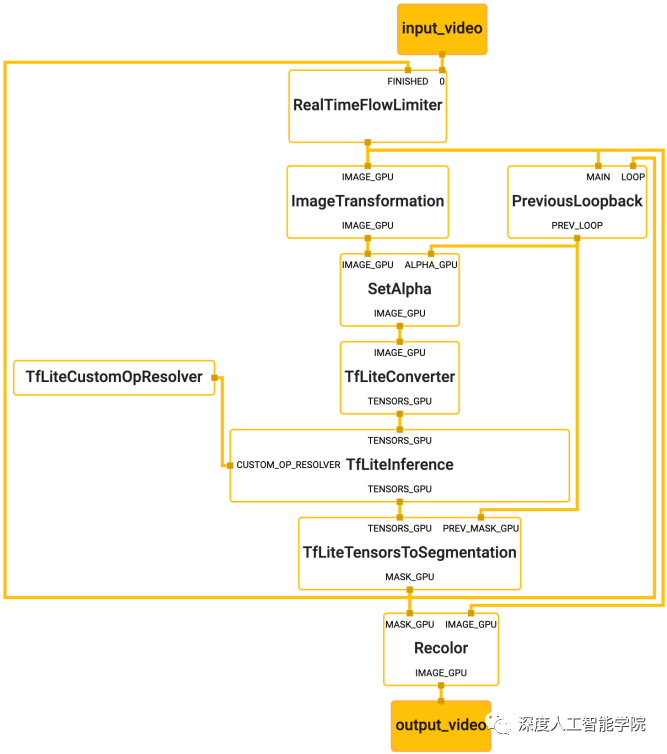
一款多媒體機器學習應用的成敗除了依賴于模型本身的好壞,還取決于設備資源的有效調配、多個輸入流之間的高效同步、跨平臺部署上的便捷程度、以及應用搭建的快速與否。
基于這些需求,谷歌開發并開源了 項目。除了上述的特性, 還支持 和 TF Lite 的推理引擎( Engine),任何 和 TF Lite 的模型都可以在 上使用。同時,在移動端和嵌入式平臺, 也支持設備本身的 GPU 加速。
專為機器學習(ML)從業者而設計,包括研究人員,學生和軟件開發人員,他們實施生產就緒的 ML 應用程序,發布伴隨研究工作的代碼,以及構建技術原型。 的主要用例是使用推理模型和其他可重用組件對應用機器學習管道進行快速原型設計。 還有助于將機器學習技術部署到各種不同硬件平臺上的演示和應用程序中。
的核心框架由 C++ 實現,并提供 Java 以及 C 等語言的支持。 的主要概念包括數據包(Packet)、數據流(Stream)、計算單元()、圖(Graph)以及子圖()。數據包是最基礎的數據單位,一個數據包代表了在某一特定時間節點的數據,例如一幀圖像或一小段音頻信號;數據流是由按時間順序升序排列的多個數據包組成,一個數據流的某一特定時間戳()只允許至多一個數據包的存在;而數據流則是在多個計算單元構成的圖中流動。 的圖是有向的——數據包從數據源(Source 或者 Graph Input Stream)流入圖直至在匯聚結點(Sink 或者 Graph Output Stream) 離開。
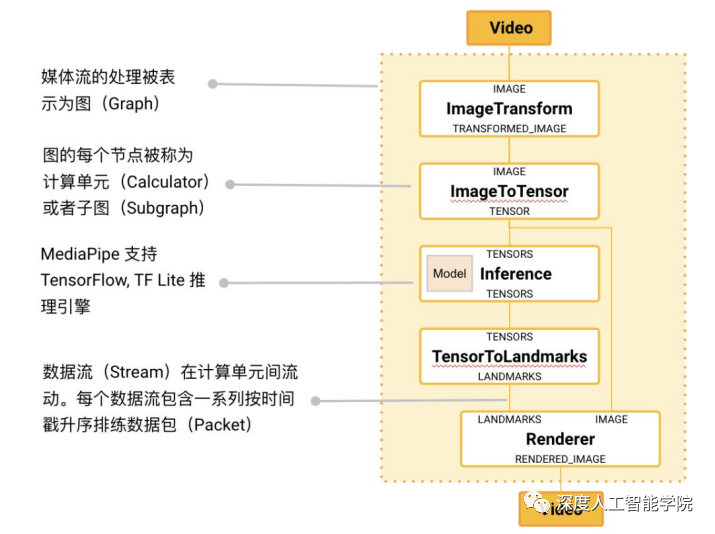
在開源了多個由谷歌內部團隊實現的計算單元()的同時,也向用戶提供定制新計算單元的接口。創建一個新的 ,需要用戶實現 Open(),Process(),Close() 去分別定義 的初始化,針對數據流的處理方法,以及 在完成所有運算后的關閉步驟。為了方便用戶在多個圖中復用已有的通用組件,例如圖像數據的預處理、模型的推理以及圖像的渲染等, 引入了子圖()的概念。因此,一個 圖中的節點既可以是計算單元,亦可以是子圖。子圖在不同圖內的復用,方便了大規模模塊化的應用搭建。
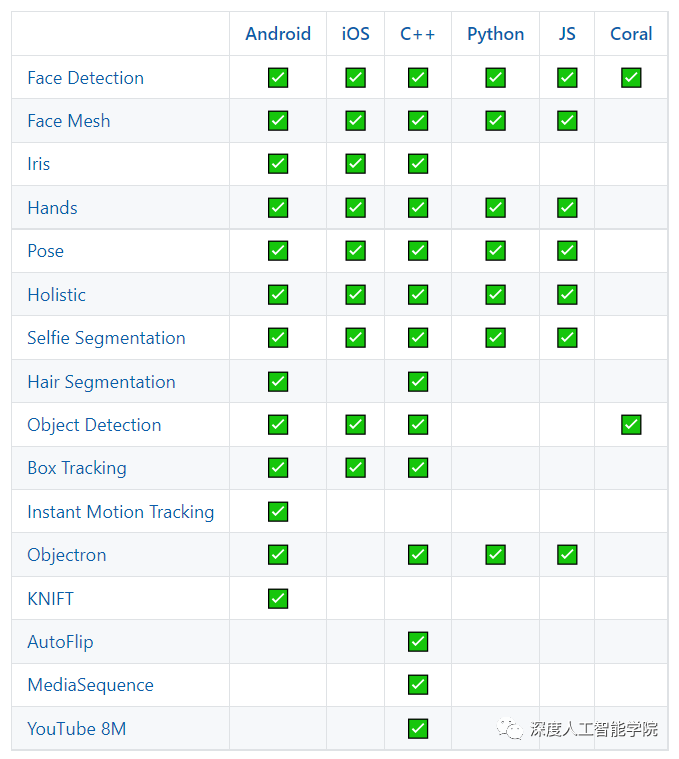
不支持除了之外的其他深度學習框架,但是對各種系統平臺和語言的支持非常友好:
的官方地址:
GitHub地址:
ONNX
Open Neural Network (ONNX,開放神經網絡交換)格式,是一個用于表示深度學習模型的標準,可使模型在不同框架之間進行轉移。ONNX是一種針對機器學習所設計的開放式的文件格式,用于存儲訓練好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存儲模型數據并交互。ONNX的規范及代碼主要由微軟,亞馬遜 , 和 IBM 等公司共同開發,以開放源代碼的方式托管在Github上。目前官方支持加載ONNX模型并進行推理的深度學習框架有:Caffe2, PyTorch, MXNet,ML.NET, 和 CNTK,并且 也非官方的支持ONNX。
比方說現在某組織因為主要開發用為基礎的框架,現在有一個深度算法,需要將其部署在移動設備上,以觀測變現。傳統地我們需要用caffe2重新將模型寫好,然后再訓練參數;試想下這將是一個多么耗時耗力的過程。
此時,ONNX便應運而生,Caffe2,PyTorch, Toolkit,Apache MXNet等主流框架都對ONNX有著不同程度的支持。這就便于了我們的算法及模型在不同的框架之間的遷移。無論你使用何種訓練框架訓練模型(比如/Pytorch/OneFlow/Paddle),在訓練完畢后你都可以將這些框架的模型統一轉換為ONNX這種統一的格式進行存儲。
開放式神經網絡交換(ONNX)是邁向開放式生態系統的第一步,它使AI開發人員能夠隨著項目的發展選擇合適的工具。ONNX為AI模型提供開源格式。它定義了可擴展的計算圖模型,以及內置運算符和標準數據類型的定義。最初的ONNX專注于推理(評估)所需的功能。ONNX解釋計算圖的可移植,它使用graph的序列化格式。它不一定是框架選擇在內部使用和操作計算的形式。例如,如果在優化過程中操作更有效,則實現可以在存儲器中以不同方式表示模型。
在獲得ONNX模型之后,模型部署人員自然就可以將這個模型部署到兼容ONNX的運行環境中去。這里一般還會設計到額外的模型轉換工作,典型的比如在Android端利用NCNN部署ONNX格式模型,那么就需要將ONNX利用NCNN的轉換工具轉換到NCNN所支持的bin和param格式。
ONNX作為一個文件格式,我們自然需要一定的規則去讀取我們想要的信息或者是寫入我們需要保存信息。ONNX使用的是這個序列化數據結構去存儲神經網絡的權重信息。熟悉Caffe或者Caffe2的同學應該知道,它們的模型存儲數據結構協議也是。
是一種輕便高效的結構化數據存儲格式,可以用于結構化數據串行化,或者說序列化。它很適合做數據存儲或數據交換格式。可用于通訊協議、數據存儲等領域的語言無關、平臺無關、可擴展的序列化結構數據格式。目前提供了 C++、Java、Python 三種語言的 API(摘自官方介紹)。
協議是一個以*.proto后綴文件為基礎的,這個文件描述了用戶自定義的數據結構。如果需要了解更多細節請參考0x7節的資料3,這里只是想表達ONNX是基于來做數據存儲和傳輸,那么自然onnx.proto就是ONNX格式文件了。
ONNX作為框架共用的一種模型交換格式,使用 二進制格式來序列化模型,可以提供更好的傳輸性能我們可能會在某一任務中將 Pytorch 或者 模型轉化為 ONNX 模型(ONNX 模型一般用于中間部署階段),然后再拿轉化后的 ONNX模型進而轉化為我們使用不同框架部署需要的類型,ONNX 相當于一個翻譯的作用。

ONNX將每一個網絡的每一層或者說是每一個算子當作節點Node,再由這些Node去構建一個Graph,相當于是一個網絡。最后將Graph和這個onnx模型的其他信息結合在一起,生成一個model,也就是最終的.onnx的模型。
構建一個簡單的onnx模型,實質上,只要構建好每一個node,然后將它們和輸入輸出超參數一起塞到graph,最后轉成model就可以了。
在計算方面,雖然更高級的表達不同,但不同框架產生的最終結果都是非常接近。因此實時跟蹤某一個神經網絡是如何在這些框架上生成的,接著使用這些信息創建一個通用的計算圖,即符合ONNX標準的計算圖。
ONNX為可擴展的計算圖模型、內部運算器()以及標準數據類型提供了定義。在初始階段,每個計算數據流圖以節點列表的形式組織起來,構成一個非循環的圖。節點有一個或多個的輸入與輸出。每個節點都是對一個運算器的調用。圖還會包含協助記錄其目的、作者等信息的元數據。運算器在圖的外部實現,但那些內置的運算器可移植到不同的框架上,每個支持ONNX的框架將在匹配的數據類型上提供這些運算器的實現。
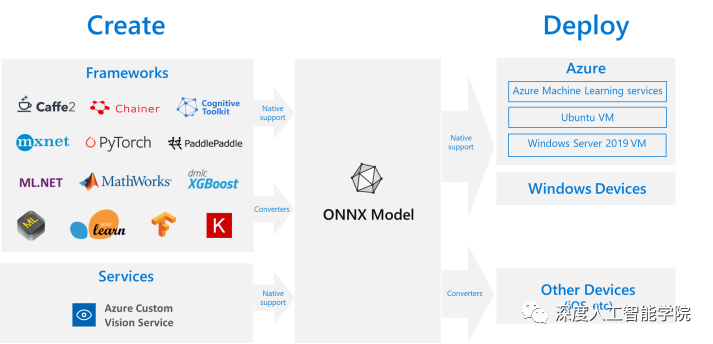
和合作伙伴社區創建了 ONNX 作為表示機器學習模型的開放標準。 許多框架(包括 、PyTorch、SciKit-Learn、Keras、Chainer、MXNet、MATLAB 和 SparkML)中的模型都可以導出或轉換為標準 ONNX 格式。模型采用 ONNX 格式后,可在各種平臺和設備上運行。
ONNX 運行時是一種用于將 ONNX 模型部署到生產環境的高性能推理引擎。它針對云和 Edge 進行了優化,適用于 Linux、Windows 和 Mac。它使用 C++ 編寫,還包含 C、Python、C#、Java 和 (Node.js) API,可在各種環境中使用。ONNX 運行時同時支持 DNN 和傳統 ML 模型,并與不同硬件上的加速器(例如,NVidia GPU 上的 、Intel 處理器上的 、Windows 上的 等)集成。通過使用 ONNX 運行時,可以從大量的生產級優化、測試和不斷改進中受益。
ONNX 運行時用于大規模 服務,如必應、Office 和 Azure 認知服務。性能提升取決于許多因素,但這些 服務的 CPU 平均起來可實現 2 倍的性能提升。除了 Azure 機器學習服務外,ONNX 運行時還在支持機器學習工作負荷的其他產品中運行,包括:
l Windows:該運行時作為 Windows 機器學習的一部分內置于 Windows 中,在數億臺設備上運行。
l Azure SQL 產品系列:針對 Azure SQL Edge 和 Azure SQL 托管實例中的數據運行本機評分。
l ML.NET:在 ML.NET 中運行 ONNX 模型。
ONNX的官方網站:
ONXX的GitHub地址:
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
