整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
關于檢索增強生成(RAG)的文章已經有很多了,如果我們能創建出可訓練的檢索器,或者說整個RAG可以像微調大型語言模型(LLM)那樣定制化的話,那肯定能夠獲得更好的結果。但是當前RAG的問題在于各個子模塊之間并沒有完全協調,就像一個縫合怪一樣,雖然能夠工作但各部分并不和諧,所以我們這里介紹RAG 2.0的概念來解決這個問題。
什么是RAG?
簡單來說,RAG可以為我們的大型語言模型(LLM)提供額外的上下文,以生成更好、更具體的回應。LLM是在公開可用的數據上訓練的,它們本身是非常智能的系統,但它們無法回答具體問題,因為它們缺乏回答這些問題的上下文。
所以RAG可以向LLM插入新知識或能力,盡管這種知識插入并不是永久的。而另一種常用向LLM添加新知識或能力的方法是通過對我們特定數據進行微調LLM。
通過微調添加新知識相當困難,昂貴,但是卻是永久性。通過微調添加新能力甚至會影響它以前擁有的知識。在微調過程中,我們無法控制哪些權重將被改變,因此也無法得知哪些能力會增加或減少。
選擇微調、RAG還是兩者的結合,完全取決于手頭的任務。沒有一種適合所有情況的方法。
RAG的經典步驟如下:
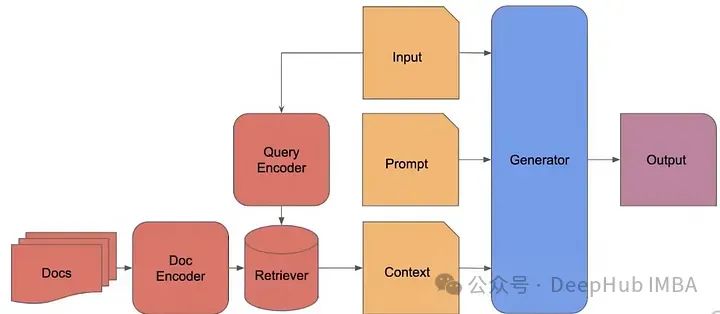
RAG 2.0
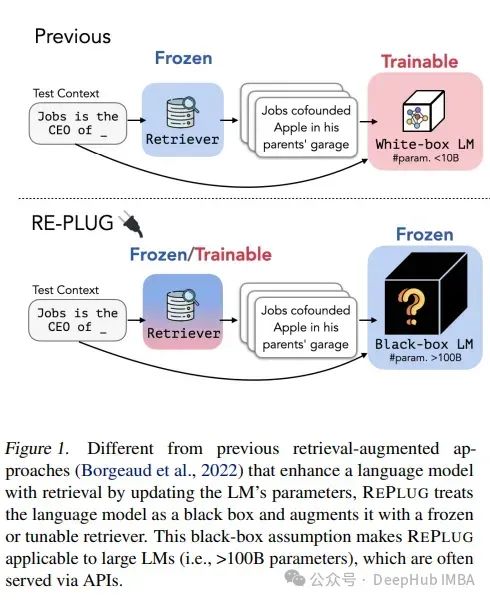
當今典型的RAG系統使用現成的凍結模型進行嵌入,使用向量數據庫進行檢索,以及使用黑盒語言模型進行生成,通過提示或編排框架將它們拼接在一起。各個組件技術上可行,但整體遠非最佳。這些系統脆弱,缺乏對其部署領域的任何機器學習或專業化,需要廣泛的提示,并且容易發生級聯錯誤。結果是RAG系統很少通過生產標準。
而我們要說的RAG 2.0的概念,通過預訓練、微調并對所有組件進行對齊,作為一個整體集成系統,通過語言模型和檢索器的雙重反向傳播來最大化性能:
下面就是我們將上下文語言模型( Models)與凍結模型的 RAG 系統在多個維度進行比較
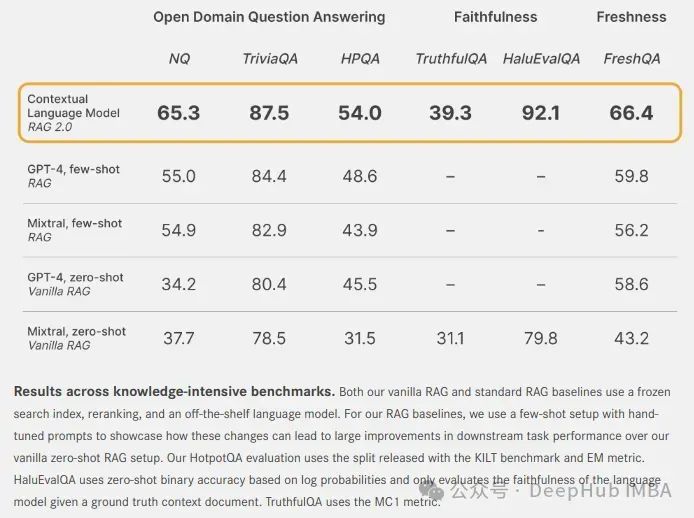
對于開放域問答:使用標準的自然問題(NQ)和 數據集來測試每個模型檢索相關知識和準確生成答案的能力。還在單步檢索設置中使用 (HPQA)數據集對模型進行評估。所有數據集都使用精確匹配(EM)指標。
對于忠實度:使用 和 來衡量每個模型在檢索證據和幻覺中保持基礎的能力。
而新鮮度:我們使用網絡搜索索引來衡量每個 RAG 系統概括快速變化的世界知識的能力,并在最新的 FreshQA 基準測試中顯示準確性。
這些維度對于構建生產級別的 RAG 系統非常重要。CLM 在多種強大的凍結模型RAG 系統上顯著提升性能,這些系統是使用 GPT-4 或最先進的開源模型如 Mixtral 構建的。
RAG如何解決智能問題?
RAG是一種半參數系統,其中參數部分是大型語言模型(LLM),其余部分是非參數的。這樣我們就得到了半參數系統。LLM在其權重或參數中存儲了所有信息(以編碼形式),而系統的其余部分則沒有定義這些知識的參數。
但這為什么能解決問題呢?
所以RAG為的LLM提供了更好的上下文化能力,使其表現良好。但實際上真的這么簡單嗎?
并不是,因為我們有許多需要解答的問題,才能創建一個現代化的可擴展的RAG管道。
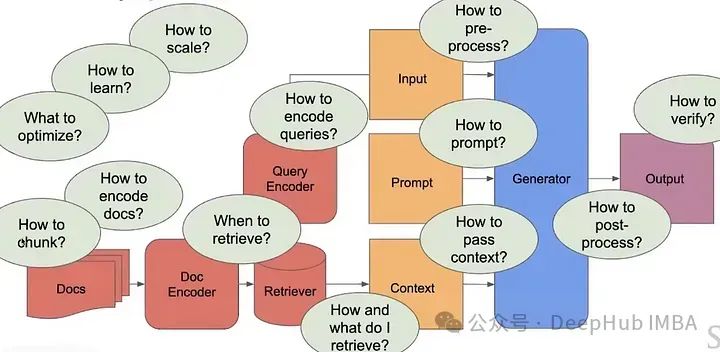
當前的RAG系統并沒有那么智能,而且它們非常簡單,無法解決需要大量自定義上下文的復雜任務。
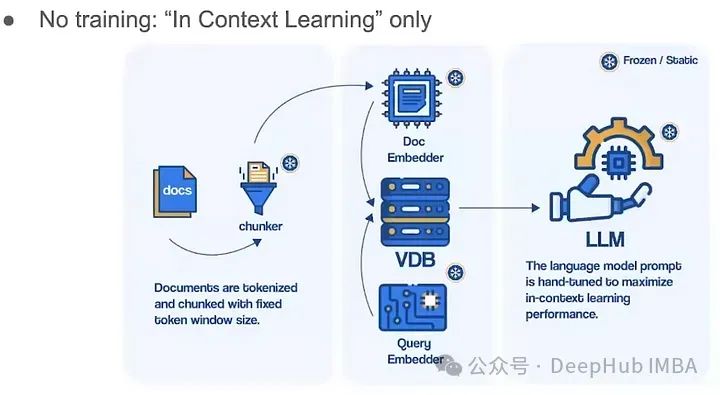
我們看到,目前唯一可以訓練的參數部分就是LLM。能否增加更多的參數呢?
更好的檢索策略
1、稀疏檢索
TF-IDF:TF-IDF或詞頻-逆文檔頻率,是衡量一個詞對一個文檔集或語料庫中的文檔的重要性的指標,同時調整了某些詞通常出現得更頻繁的事實。[1] 它常被用作信息檢索、文本挖掘和用戶建模搜索中的權重因子。


BM25:可以視為對TF-IDF的改進。
對于查詢“機器學習”,BM25的計算將是(機器) + (學習)的總和。
公式的第一部分是詞項的逆文檔頻率(IDF)。公式的第二部分代表詞頻(TF),該詞頻通過文檔長度進行了標準化。
f(q(i), D) 是文檔 D 中詞 q(i) 的詞頻。
K 和 b 是可以調整的參數。|D| 表示文檔的長度,avgdl 表示數據庫中所有文檔的平均長度。
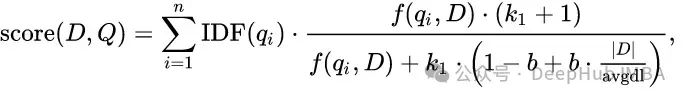
這些是稀疏檢索的一些早期步驟。
2、密集檢索
需要密集檢索的原因是因為語言并不那么直白。例如,如果有同義詞,稀疏檢索就會完全失效。我們不僅僅想基于確切關鍵詞匹配來檢索信息,更多的是基于句子的語義。BERT 就是一個密集檢索的例子。將句子轉換為向量后,使用點積或余弦相似度來檢索信息。
密集檢索的一個好處是它易于并行處理,借助GPU,它可以輕松地在十億級別的相似性搜索上運行,這就是Meta開發FAISS的方式,或者我們常說的向量數據庫。
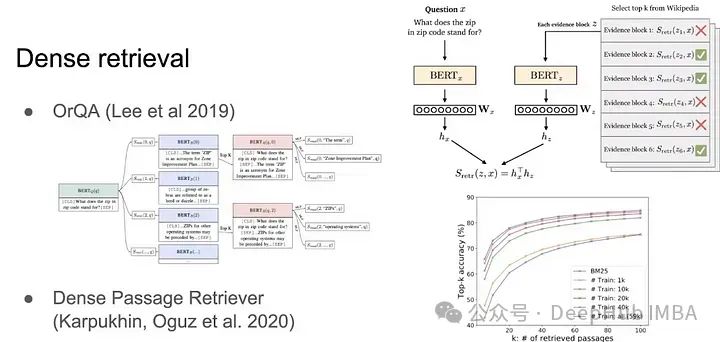
密集檢索也就是我們常說的向量查詢,它通常使用點積來判斷響亮的相似程度,這也是一般RAG中常用的步驟。我們如何超越簡單的點積呢?
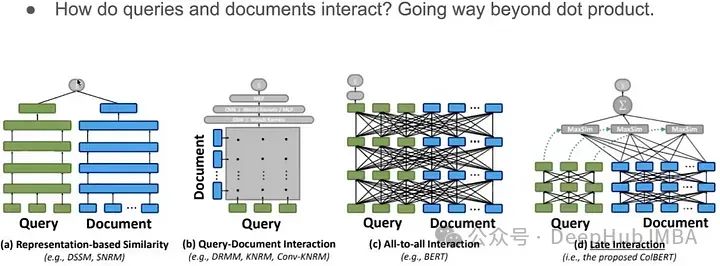
除了簡單的點積以外,還有很多文檔和查詢交互方式,比如說 孿生網絡,ColBERT,等等
基于模型的檢索算法
ColBERT是一個非常好的檢索策略,但這并不是信息檢索的SOTA。我們還有其他更先進的算法和策略,如SPLADE、DRAGON和Hybrid搜索。
1、SPLADE:稀疏與密集的結合的查詢擴展。

可以看到,通過查詢擴展,涵蓋了更多的上下文,這有助于更好的檢索。
2、DRAGON:通過漸進式數據增強來推廣密集檢索器。
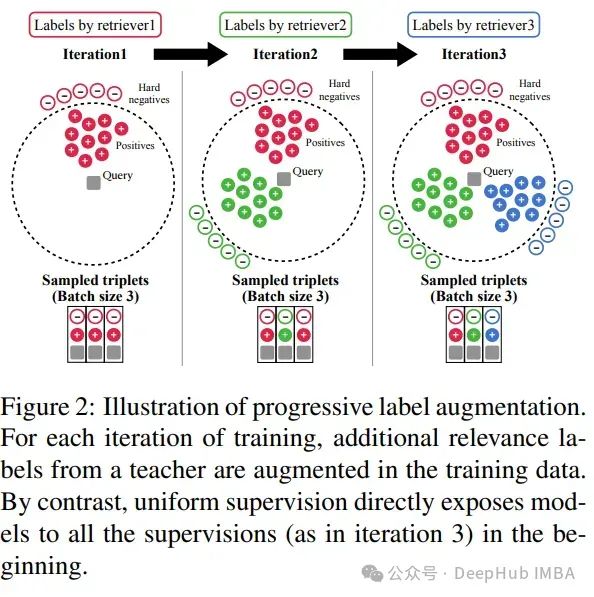
讓我們通過一個例子來理解DRAGON的工作原理:
DRAGON根據用戶在對話中不斷變化的興趣動態調整其檢索查詢。用戶的每一次輸入都會實時更新檢索過程,確保提供的信息既相關又詳細,符合最新的上下文。
3、混合搜索:我們在密集和稀疏搜索之間進行插值。這就是RAG社區一直在研究的方向,比如采用類似BM25的并將其與SPLADE或DRAGON結合。
但是無論我們使用什么方法,檢索器仍然是固定的,或者說無法定制(微調)的
可以提供上下文的檢索器
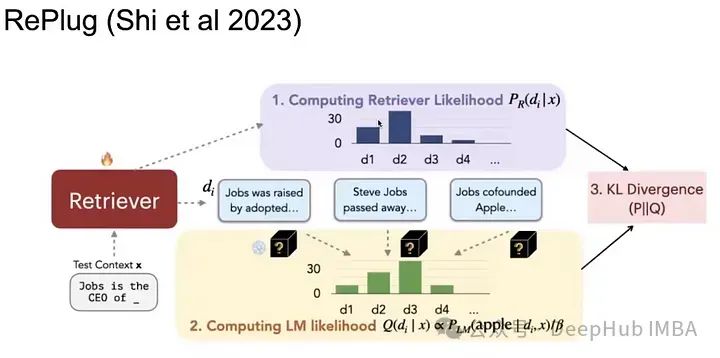
1、RePlug
這是一篇關于檢索的非常有趣的論文,對于給定的查詢,我們檢索出前K個文檔,并進行歸一化(計算它們的可能性)后得到一個分布,然后我們將每個文檔與查詢一起單獨輸入給一個生成器。然后查看語言模型對正確答案的困惑度。這樣就有了兩個可能性分布,在這些分布上我們計算KL散度損失,以使KL散度最小化,就會得到檢索到的文檔與正確答案上的困惑度最低的結果。
2、In-Context RALM
它使用凍結模型RAG 和 BM25,然后通過重新排序專門化檢索部分。包含一個零樣本學習的語言模型和一個訓練過的重新排序器。

語言模型是固定的,我們只反向傳播或訓練重新排序的部分。這不是很先進,但與前面的簡單RAG相比,它的性能還不錯。
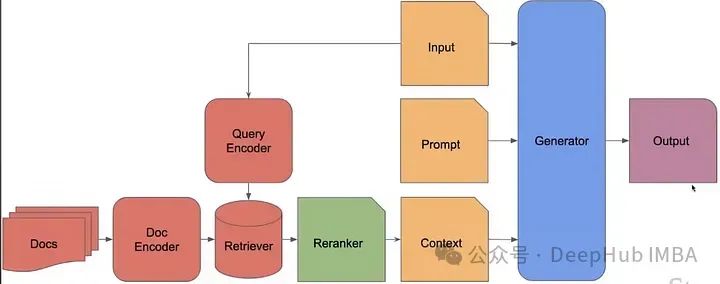
但問題是如果無法訪問LLM的參數,如何對檢索器的參數進行反向傳播或更新呢?
所以它是使用強化風格的損失來訓練檢索器。檢索器的有效性通過其獲取的信息如何增強語言模型的輸出來評判。對檢索器的改進集中在最大化這種增強上。這可能涉及基于從語言模型輸出中派生的性能指標調整檢索策略(獲取信息的內容和方式)。常見的指標可能包括生成文本的連貫性、相關性和事實準確性。
3、組合上下文化檢索器和生成器
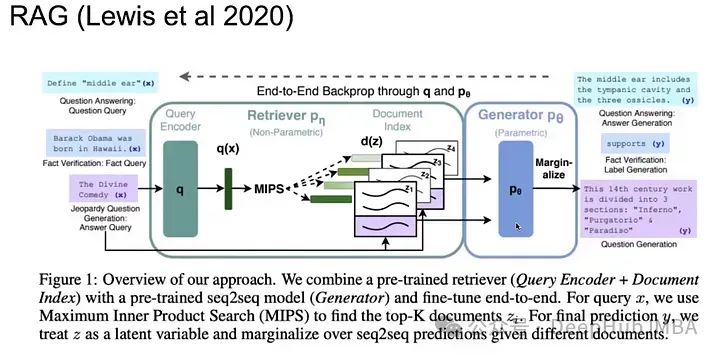
與其單獨優化LLM或,不如一次優化整個流程?

當檢索文檔時,在每n個令牌或一次檢索時,有很多地方可以優化。
在RAG-token模型中,與RAG-模型的單次檢索相比,可以在不同的目標token上檢索不同的文檔。
使用編碼器對所有k個文檔進行編碼,接著進行協同,然后在將其作為上下文提供給輸入提示之前進行解碼。

4、k-NN LM
另外一個在RAG系統中有趣的想法是增加包括k-NN LM:
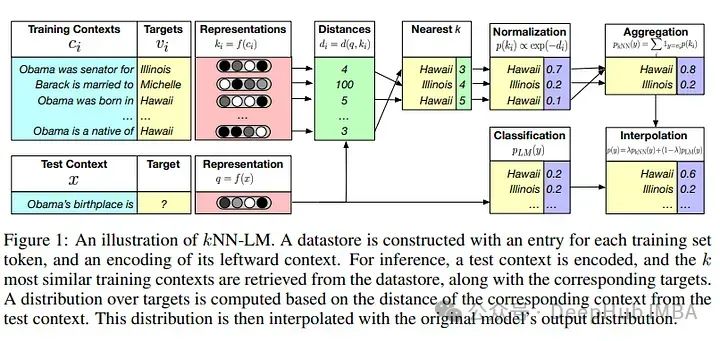
研究人員表明,如果在RAG環境中訓練,他們可以創建25倍小的模型
目前SOTA整理
大型語言模型(LLM)的上下文化既復雜又昂貴。因為重新更新整個LLM并不容易,需要更新數十億甚至數萬億的令牌。
所以Meta的FAIR的發布了ATLAS論文,這篇論文討論了可以用來訓練整個RAG管道,并且針對不同部分使用不同類型的損失函數,并對它們進行了性能比較。
以下是ATLAS論文中所有不同損失的性能比較:
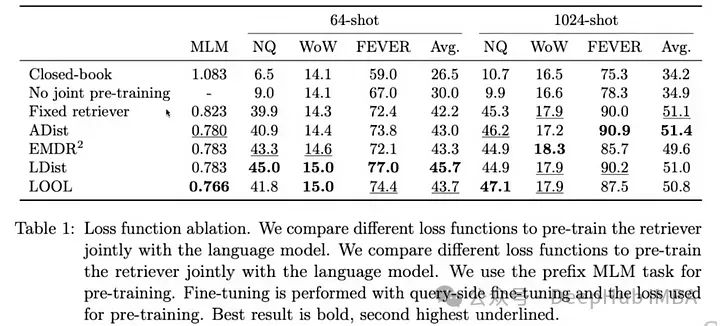
ATLAS是一個經過精心設計和預訓練的檢索增強型語言模型,能夠通過極少的訓練示例學習知識密集型任務。ATLAS將這些損失函數整合進一個連貫的訓練流程中,可以直接基于其對語言模型性能的影響來微調檢索器,而不是依賴于外部注釋或預定義的相關性評分。這種整合使系統能夠隨著時間的推移通過適應其訓練任務的具體需求而改進。
總結
RAG(檢索增強生成)有三種類型:
凍結模型RAG:這些在整個行業中隨處可見,它們只是概念驗證(POC)。半凍結模型RAG:應用智能檢索器,并試圖使它們以某種方式適應。不修改LLM只是操作檢索器并將它們與最終輸出結合。完全可訓練的RAG:端到端訓練相當困難,但如果做得正確,可以提供最佳性能。但是肯定非常消耗資源。
而我們常用的RAG還僅僅是第一種凍結模型RAG,所以說RAG的技術目前還處于初級階段,擴展語言模型的參數還是令牌,如何有效地擴展檢索器,通過參數還是數據塊將記憶與概括分離,將知識檢索與生成過程分離等,都是后續需要繼續研究的問題。
win10系統修改文件后綴名的方法
win10系統應該大家都是不陌生的,而且目前使用win10系統的小伙伴占比很多,經常使用win10系統的小伙伴應該知道,win10系統是一個可以進行自動更新且提供的功能也十分智能的操作系統,當我們在進行文件的編輯時,有些時候保存在電腦中的文件的后綴名不是自己喜歡的,想要將后綴名重新更改一下,那么我們就可以直接對文件進行重命名即可,將文件的后綴名格式更改成自己需要的格式就好了,下方是關于如何使用win10系統更改文件格式的具體操作方法,如果你需要的情況下可以看看方法教程,希望對大家有所幫助。
方法步驟
1.比如小編以圖片文件為例進行演示一下,當前的圖片是png圖片,如圖所示。

2.你可以將該圖片進行重命名,之后就可以對文件名稱進行修改了,我們直接將后綴名修改成【jpg】即可,如圖所示。
3.之后會彈出一個提示窗口,修改了文件擴展名的話,可能會導致文件不可用的情況,這里我們直接點擊【是】按鈕即可。
4.之后,我們將已經修改好的文件進行雙擊一下,這時你可以看到我們的文件是可以進行正常查看和瀏覽的,如圖所示。
5.此外,你還可以將文件進行右鍵點擊選中,然后在旁邊彈出的菜單選項中,將【屬性】選項進行點擊一下。
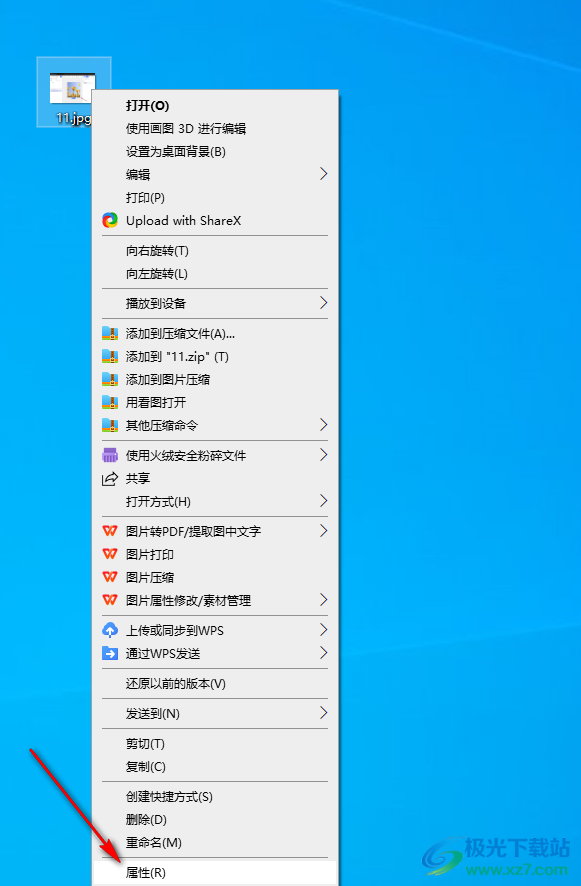
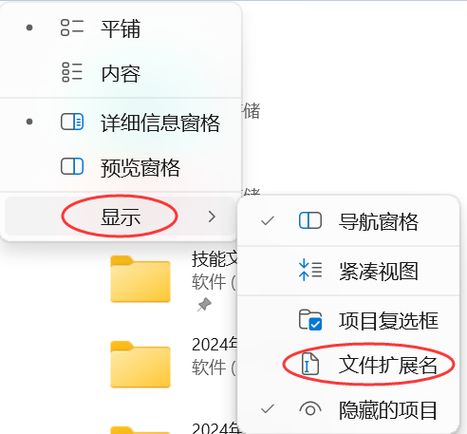
6.隨后在頁面上彈出的屬性窗口中,你可以在常規選項卡下,將文件名后面的后綴名進行修改成自己需要的文件格式即可。
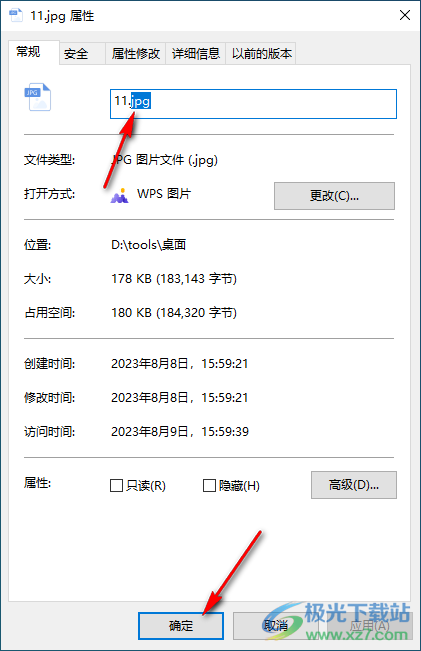
以上就是關于如何使用win10系統修改文件格式的具體操作方法,以上修改文件格式的方法是很簡單的,但是小編需要提醒一下大家,按照上述方法可以將同種類型的文件進行格式的修改,但是如果不同類型的文件進行格式的修改可能就會導致文件打不開的情況,比如將圖片格式的后綴名更改成視頻格式的后綴名可能就會無法打開文件,感興趣的話可以操作試試。

家庭中文版4.00 GB / 64位單語言版
下載
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
