整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
加入極市專業CV交流群,與6000+來自騰訊,華為,百度,北大,清華,中科院等名企名校視覺開發者互動交流!更有機會與李開復老師等大牛群內互動!
同時提供每月大咖直播分享、真實項目需求對接、干貨資訊匯總,行業技術交流。關注極市平臺公眾號,回復加群,立刻申請入群~
導讀
卷積是深度學習中的基礎運算,那么卷積運算是如何加速到這么快的呢,掰開揉碎了給你看。

在我不太破舊的筆記本電腦CPU上,使用這樣的庫,我可以(最多)在10-100毫秒內運行大多數常見的CNN模型。在2019年,即使是智能手機也能在不到半秒的時間內運行“重”CNN(比如ResNet)模型。所以,想象一下當給我自己的卷積層的簡單實現計時的時候,我很驚訝,發現它為一個單層花費了2秒!
現代深度學習庫對大多數操作都具有生產級的、高度優化的實現,這并不奇怪。但這些庫究竟是什么魔法?他們如何能夠將性能提高100倍?究竟怎樣才能“優化”或加速神經網絡的運行呢?在討論高性能/高效DNNs時,我經常會問(也經常被問到)這些問題。
在這篇文章中,我將嘗試帶你了解在DNN庫中卷積層是如何實現的。它不僅是在模型中最常見的和最重的操作,我還發現卷積高性能實現的技巧特別具有代表性——一點點算法的小聰明,非常多的仔細的調優和低層架構的開發。
我在這里介紹的很多內容都來自Goto等人的開創性論文:Anatomy of a high- matrix ,該論文為等線性代數庫中使用的算法奠定了基礎。
最原始的卷積實現
“過早的優化是萬惡之源”——Donald Knuth
在進行優化之前,我們先了解一下基線和瓶頸。這是一個樸素的numpy/for循環卷積:
'''
Convolve `input` with `kernel` to generate `output`
input.shape = [input_channels, input_height, input_width]
kernel.shape = [num_filters, input_channels, kernel_height, kernel_width]
output.shape = [num_filters, output_height, output_width]
'''
for filter in 0..num_filters
for channel in 0..input_channels
for out_h in 0..output_height
for out_w in 0..output_width
for k_h in 0..kernel_height
for k_w in 0..kernel_width
output[filter, channel, out_h, out_h] +=
kernel[filter, channel, k_h, k_w] *
input[channel, out_h + k_h, out_w + k_w]這是一個6層嵌套的for循環(如果你迭代多個輸入批次,則為7個)。我們還沒有研究步幅,膨脹,或其他參數。如果我在這里輸入的第一層的大小,然后用普通的C語言運行它,它會花費驚人的22秒!使用最積極的編譯器優化,如' -O3 '或' -Ofast ',它減少到2.2秒。但這對于第一層來說仍然非常慢。
如果我使用Caffe運行相同的層呢?這臺電腦只用了18毫秒。這比100倍的加速還要快!整個網絡在我的CPU上運行大約100毫秒。
瓶頸是什么,我們應該從哪里開始優化?
最內部的循環執行兩個浮點運算(乘法和加法),對于我使用的大小,它執行了大約8516萬次,也就是說,這個卷積需要1.7億個浮點運算(MFLOPs)。根據英特爾的數據,我的CPU的最高性能是每秒800億次,也就是說,理論上它可以在0.002秒內完成這項工作。顯然,我們離這個目標還很遠,而且很明顯,這里的原始處理能力已經足夠了。
理論峰值沒有達到(從來沒有)的原因是內存訪問也需要時間—如果不能快速獲得數據,那么僅僅快速處理數據是不夠的。事實證明,上面嵌套的for循環使得數據訪問模式非常困難,這使得緩存利用率很低。
正如你將看到的,在整個討論過程中反復出現的一個問題是,我們如何訪問正在操作的數據,以及這些數據如何與存儲方式相關聯。
一些先決條件
我們對“性能”或速度的度量是吞吐量,以每秒浮點計算次數度量。具有更多浮點操作的更大操作自然會運行得更慢,因此FLOP/s速率可以使用更一致的方式來比較性能。
我們也可以用它來了解我們離CPU的最高性能有多近。在我的筆記本電腦CPU上:
其峰值性能為 GFLOP/s。這是我的CPU的理論峰值。同樣,對于單個內核,這個數字是80GFLOP/s。
雖然我們從邏輯上把矩陣/圖像/張量看作多維的,但它們實際上存儲在線性的一維計算機內存中。我們必須定義一個約定,該約定規定如何將這些多維數據展開到線性存儲中,反之亦然。
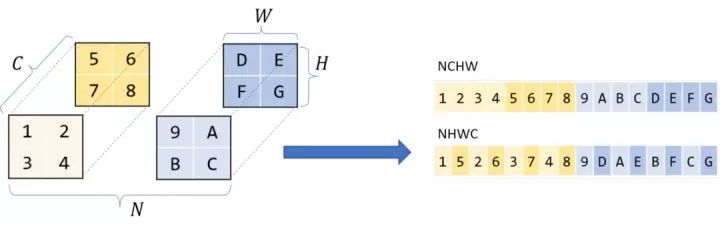
大多數現代DL庫使用行主序存儲。這意味著同一行的連續元素彼此相鄰存儲。更一般地說,對于多維,行主序意味著當線性掃描內存時,第一個維度的變化最慢。
那么維度本身的順序呢?通常對于四維張量,比如CNNs,你會聽到NCHW, NHWC等存儲順序。我將在這篇文章中假設NCHW——如果我有N塊HxW圖像的C通道,那么所有具有相同N個通道的圖像都是重疊的,在該塊中,同一通道C的所有像素都是重疊的,以此類推。
這里討論的許多優化都需要在底層使用神秘的C語法,甚至是程序集進行干預。這不僅使代碼難以閱讀,還使嘗試不同的優化變得困難,因為我們必須重新編寫整個代碼。Halide是c++中的一種嵌入式語言,它幫助抽象這些概念,并被設計用來幫助編寫快速圖像處理代碼。通過分解算法(要計算什么)和計劃(如何/何時計算),可以更容易地試驗不同的優化。我們可以保持算法不變,并使用不同的策略。
我將使用Halide來表示這些較低級別的概念,但是你應該能夠理解足夠直觀的函數名,以便理解。
從卷積到GEMM
我們上面討論的簡單卷積已經很慢了,一個更實際的實現只會因為步長、膨脹、填充等參數而變得更加復雜。我們可以繼續使用基本的卷積作為一個工作示例,但是,正如你看到的,從計算機中提取最大性能需要許多技巧—在多個層次上進行仔細的微調并充分利用現有計算機體系結構的非常具體的知識。換句話說,如果我們希望解決所有的復雜性,這將是一項艱巨的任務。
我們能不能把它轉化成一個更容易解決的問題?也許矩陣乘法?
矩陣乘法,或matmul,或 (GEMM)是深度學習的核心。它用于全連接層、RNNs等,也可用于實現卷積。
畢竟,卷積是帶有輸入padding的濾波器的點積。如果我們把濾波器放到一個二維矩陣中,把輸入的小patch放到另一個矩陣中,然后把這兩個矩陣相乘,就會得到相同的點積。與CNNs不同,矩陣乘法在過去幾十年里得到了大量的研究和優化,在許多科學領域都是一個關鍵問題。

上面將圖像塊放到一個矩陣中的操作稱為im2col ,用于圖像到列。我們將圖像重新排列成矩陣的列,使每一列對應一個應用卷積濾波器的patch。
考慮這個普通的,直接的3x3卷積:
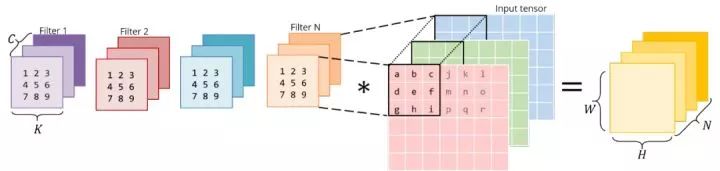
下面是與矩陣乘法相同的操作。正確的矩陣是im2col的結果——它必須通過復制原始圖像中的像素來構造。左邊的矩陣有conv權值,它們已經以這種方式存儲在內存中。
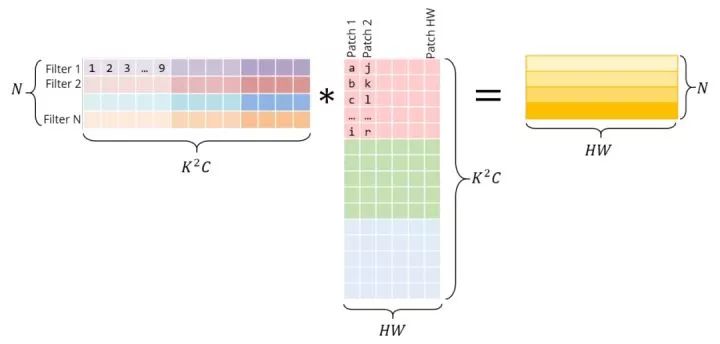
注意,矩陣乘積直接給出了conv輸出——不需要額外的“轉換”到原始形式。
為了清晰起見,我將每個patch都單獨顯示在這里。然而,在現實中,不同的圖像塊之間往往存在一定的重疊,因此im2col會產生一定的內存重復。生成這個im2col緩沖區和膨脹的內存所花費的時間,必須通過GEMM實現的加速來抵消。
利用im2col,我們已經將卷積運算轉化為矩陣乘法。我們現在可以插入更多通用的和流行的線性代數庫,如、Eigen等,利用幾十年的優化和仔細的調優,有效地計算這個matmul。
如果我們要證明im2col轉換所帶來的額外工作和內存是合理的,那么我們需要一些非常嚴重的加速,所以讓我們看看這些庫是如何實現這一點的。這也很好地介紹了在系統級進行優化時的一些通用方法。
雖然以前有過不同形式的-as-GEMM思想,但Caffe是第一個在CPU和GPU上對通用convs使用這種方法的深度學習庫之一,并顯示了較大的加速。這里:///wi一個非常有趣的閱讀來自于Yanqing Jia本人(Caffe的創始人)關于這個決定的起源,以及關于“臨時”解決方案的想法。
加速GEMM
在這篇文章的其余部分,我將假設GEMM被執行為
和之前一樣,首先讓我們對基本的,課本上的矩陣乘法進行計時:
for i in 0..M:
for j in 0..N:
for k in 0..K:
C[i, j] += A[i, k] * B[k, j]
使用Halide:
Halide::Buffer C, A, B;
Halide::Var x, y;
C(x,y) += A(k, x) *= B(y, k); // loop bounds, dims, etc. are taken care of automatically
最里面的一行執行2個浮點運算(乘法和加法),并執行M?N?K次,因此這個GEMM的FLOPs是2MNK。
我們來測量一下它在不同矩陣大小下的性能:
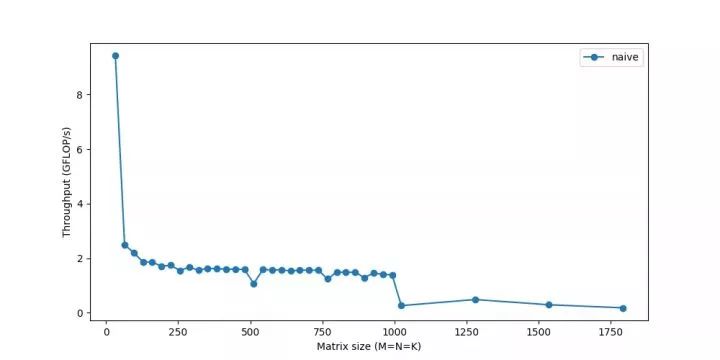
我們的性能才剛剛達到頂峰的10% !雖然我們將研究使計算更快的方法,但一個反復出現的主題是,如果我們不能快速獲得數據,僅僅快速計算數據是不夠的。由于內存對于較大的矩陣來說是一個越來越大的問題,因此性能會逐漸下降。你最后看到的急劇下降,表示當矩陣變得太大而無法放入緩存時,吞吐量突然下降—你可以看到系統阻塞。
RAM是一個大而慢的存儲器。CPU緩存的速度要快幾個數量級,但要小得多,因此正確使用它們至關重要。但是沒有明確的指令說“加載數據以緩存”。它是一個由CPU自動管理的進程。
每次從主存中獲取數據時,CPU都會自動將數據及其相鄰的內存加載到緩存中,希望利用引用的局部性。
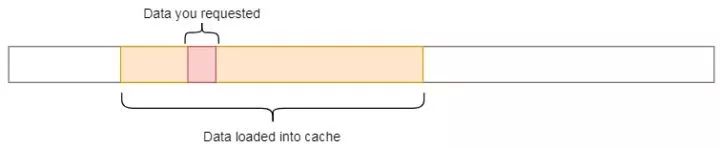
你應該注意的第一件事是我們訪問數據的模式。我們在A上按行遍歷,在B上按列遍歷。
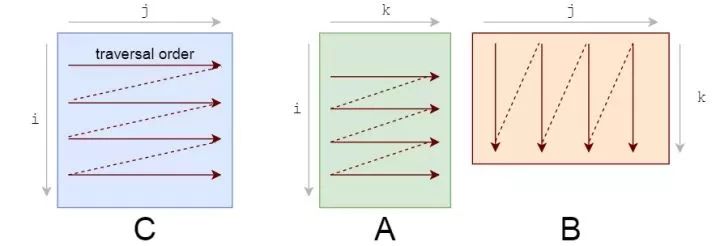
它們的存儲也是行主序的,所以一旦找到A[i, k],行中的下一個元素A[i, k+1]就已經緩存了。酷。但看看B會發生什么:
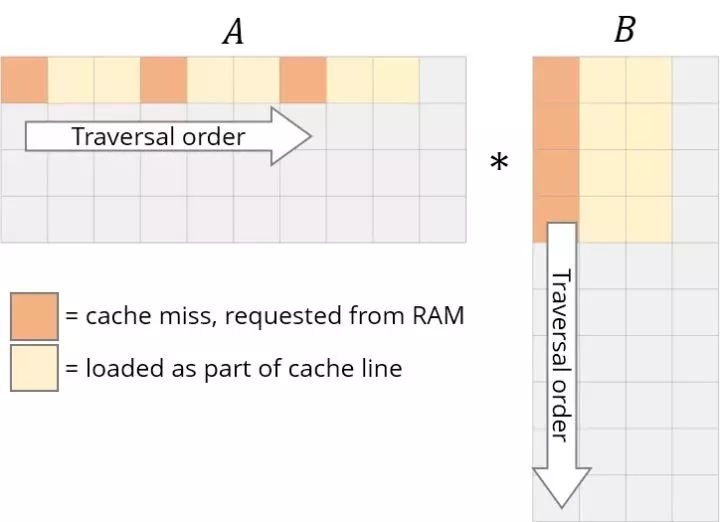
我們需要重新設計循環來利用這種緩存能力。如果正在讀取數據,我們不妨利用它。這是我們要做的第一個更改:循環重新排序。
讓我們重新排序循環,從i,j,k到i,k,j:
for i in 0..M:
for k in 0..K:
for j in 0..N:
我們的答案仍然是正確的,因為乘法/加法的順序無關緊要。遍歷順序現在看起來是這樣的:
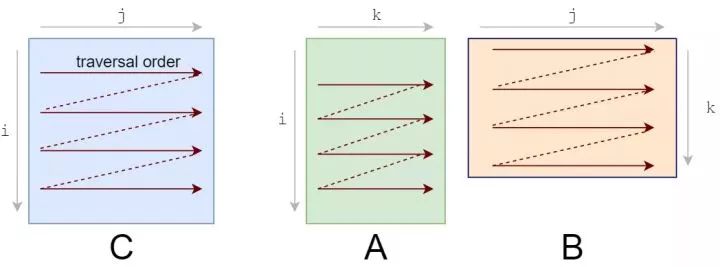
這個簡單的改變,只是重新排序了一下循環,給了一個相當快的加速:
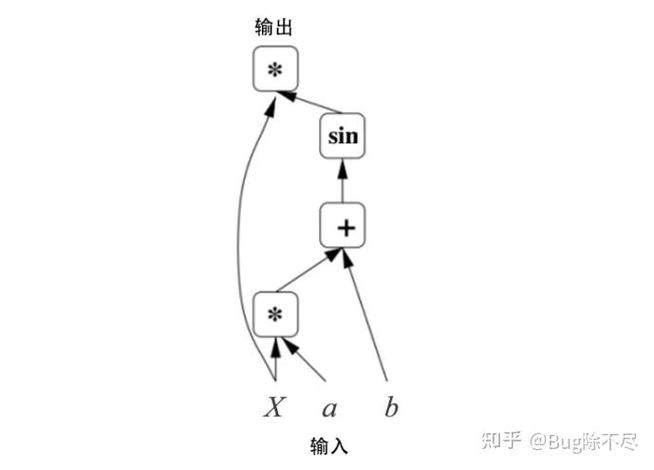
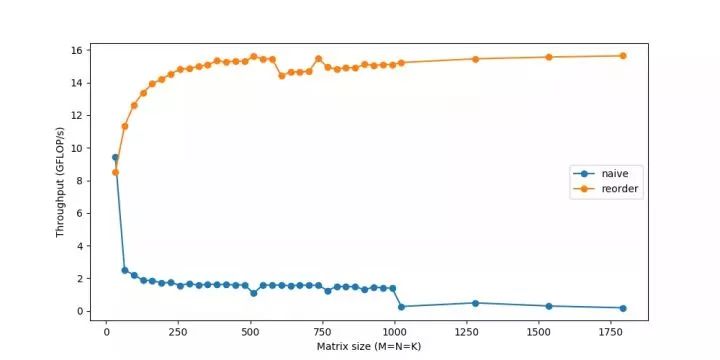
為了進一步改進重新排序,我們還需要考慮一個緩存問題。
對于A的每一行,我們循環遍歷整個B。在B中每進行一步,我們將加載它的一些新列并從緩存中刪除一些舊列。當我們到達A的下一行時,我們從第一列開始重新開始。我們重復地從緩存中添加和刪除相同的數據,這叫做抖動。
如果我們所有的數據都能放入緩存,就不會發生抖動。如果我們使用更小的矩陣,他們就可以幸福地生活在一起,而不會被反復驅逐。謝天謝地,我們可以分解子矩陣上的矩陣乘法。計算一個C中的小的r×c塊,只需要A中的r行和B中的C列。讓我們把C分成6x16的小塊。
C(x, y) += A(k, y) * B(x, k);
C.update()
.tile(x, y, xo, yo, xi, yi, 6, 16)
/*
in pseudocode:
for xo in 0..N/16:
for yo in 0..M/6:
for yi in 6:
for xi in 0..16:
for k in 0..K:
C(...) = ...
*/
我們已經把x,y的維度分解成外部的xo,yo和內部的xi,yi。我們將努力為較小的6x16塊(標記為xi,yi)優化一個微內核,并在所有塊上運行該微內核(由xo,yo迭代)。
& FMA
大多數現代cpu都支持SIMD,或者。顧名思義,SIMD可以在相同的CPU周期內對多個值同時執行相同的操作/指令(如add、等)。如果我們可以一次運行4個數據點上的SIMD指令,那么就可以實現4倍的加速。
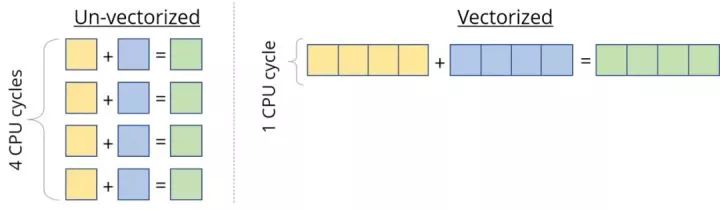
因此,當我們計算處理器的峰值速度時,我們“有點”作弊,而是參考了這種向量化的性能。這對于像向量這樣的數據非常有用,我們必須對每個向量元素應用相同的指令。但是我們仍然需要設計內核來正確地利用這一點。
我們在計算峰值故障時使用的第二個“hack”是FMA--Add。雖然乘法和加法被算作兩個獨立的浮點運算,但它們是如此常見,以至于可以使用專用的硬件單元來“融合”它們,并將它們作為一條指令執行。使用它通常由編譯器處理。
在Intel cpu上,我們可以使用SIMD(稱為AVX & SSE)在一條指令中處理多達8個浮點數。編譯器優化通常能夠自己識別向量化的機會,但為了確保這一點,我們將親自動手。
C.update()
.tile(x, y, xo, yo, xi, yi, 6, 16)
.reorder(xi, yi, k, xo, yo)
.vectorize(xi, 8)
/*
in pseudocode:
for xo in 0..N/16:
for yo in 0..M/6:
for k in 0..K:
for yi in 6:
for vectorized xi in 0..16:
C(...) = ...
*/

到目前為止,我們只使用了一個CPU內核。我們有多個可用的內核,每個內核可以同時物理地執行多個指令。一個程序可以把自己分成多個線程,每個線程可以運行在一個單獨的內核上。
C.update()
.tile(x, y, xo, yo, xi, yi, 6, 16)
.reorder(xi, yi, k, xo, yo)
.vectorize(xi, 8)
.parallel(yo)
/*
in pseudocode:
for xo in 0..N/16 in steps of 16:
for parallel yo in steps of 6:
for k in 0..K:
for yi in 6:
for vectorized xi in 0..16 in steps of 8:
C(...) = ...
*/
你可能會注意到,對于非常小的大小,性能實際上會下降,因為在較小的工作負載下,線程的工作時間更少,而彼此同步的時間更多。在線程方面還有很多其他類似的問題,它們本身可能需要進一步深入研究。
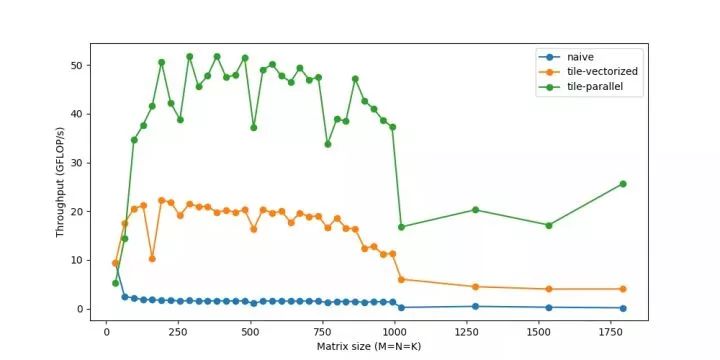
循環讓我們避免了一遍又一遍地編寫同一行的痛苦,同時引入了一些額外的工作,比如檢查循環終止、更新循環計數器、指針算法等。相反,如果我們手工編寫重復循環語句并展開循環,我們可以減少這種開銷。例如,我們可以運行包含4個語句的2個迭代,而不是1個語句的8個迭代。
起初,我感到驚訝的是,如此反復無常、看似微不足道的管理費用,實際上卻很重要。然而,盡管這些循環操作可能“便宜”,但它們肯定不是免費的。如果你還記得這里迭代的數量是以百萬為單位的,那么每次迭代額外的2-3條指令的成本將很快增加。當循環開銷變得相對較小時,好處會逐漸減少。
展開是另一個優化,現在幾乎完全由編譯器來處理,除了在像我們這樣的微內核中,我們更喜歡控制。
C.update()
.tile(x, y, xo, yo, xi, yi, 6, 16)
.reorder(xi, yi, k, xo, yo)
.vectorize(xi, 8)
.unroll(xi)
.unroll(yi)
/*
in pseudocode:
for xo in 0..N/16:
for parallel yo:
for k in 0..K:
C(xi:xi+8, yi+0)
C(xi:xi+8, yi+1)
...
C(xi:xi+8, yi+5)
C(xi+8:xi+16, yi+0)
C(xi+8:xi+16, yi+1)
...
C(xi+8:xi+16, yi+5)
*/
我們現在可以達到60GFLOP/s。
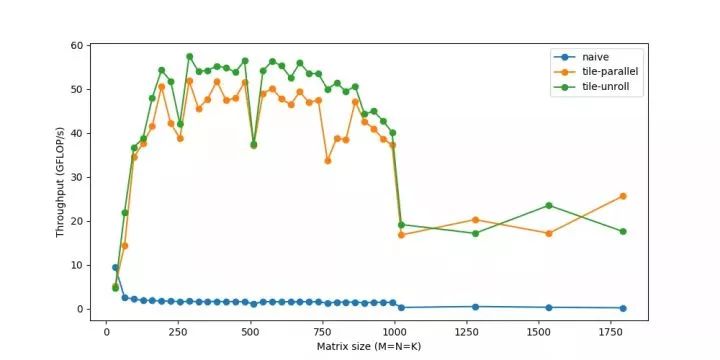
全部放到一起
上面的步驟涵蓋了一些最常用的轉換來提高性能。它們通常以不同的方式組合在一起,從而產生越來越復雜的策略來計算相同的任務。
這是來自Halide 的一個更仔細優化的策略。
matrix_mul(x, y) += A(k, y) * B(x, k);
out(x, y) = matrix_mul(x, y);
out.tile(x, y, xi, yi, 24, 32)
.fuse(x, y, xy).parallel(xy)
.split(yi, yi, yii, 4)
.vectorize(xi, 8)
.unroll(xi)
.unroll(yii);
matrix_mul.compute_at(out, yi)
.vectorize(x, 8).unroll(y);
matrix_mul.update(0)
.reorder(x, y, k)
.vectorize(x, 8)
.unroll(x)
.unroll(y)
.unroll(k, 2);
總結一下,它是這樣做的:
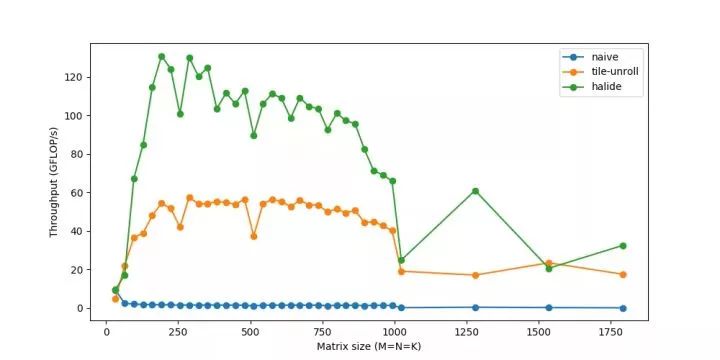
最后,我們能夠達到超過的速度—相當接近160 GFLOPs的峰值性能,并且能夠匹配等生產級庫。使用類似的im2col微調代碼,然后是gemm,相同的卷積現在運行時間為~20ms。如果你對這方面的研究感興趣,可以嘗試使用你自己的不同策略—作為一名工程師,我總是聽到關于緩存、性能等方面的說法,看到它們的真實效果可能是有益的和有趣的。
注意,這種im2col+gemm方法是大多數深度學習庫中流行的通用方法。然而,定制化是關鍵——對于特定的常用大小、不同的體系結構(GPU)和不同的操作參數(如膨脹、分組等),這些庫可能會再次使用針對這些情況的類似技巧或假設進行更定制化的實現。這些微內核是經過反復試驗和錯誤的高度迭代過程構建的。程序員通常只對什么應該/不應該工作得很好有一種直覺,并且/或者必須基于結果考慮解釋。聽起來很適合深度學習研究,對吧?
英文原文鏈接:
ie瀏覽器的箭頭如何取消 IE瀏覽器輸入法不能切換
1、ie瀏覽器的箭頭如何取消
1、用鼠標右鍵單擊桌面空白處,從彈出菜單中選擇“屬性”。
2、在打開的“顯示屬性”窗口中選擇“外觀”選項卡。
3、點擊“項目”中的下拉箭頭。
4、從中選擇“圖標”,這時旁邊的“大小”選項由本來的灰色變為可用,其值為Windows的默認值“32”,將這個值改為“30”或者更小一些,但不要小于24。
5、然后單擊下面的“確定”按鈕。
2、IE瀏覽器輸入法不能切換
1、點擊開始中的控制面板。
2、找尋到區域和語言選項,雙擊進入。
3、點擊語言中的詳細信息,進入詳細信息。
4、點擊點鍵設置。
5、點擊進去鍵設置的選項,然后點更改按鍵順序,將其調成切換鍵盤布局即可。
3、ie內核怎么設置
ie內核設置步驟如下:
1、如果用“IE”、“傲游2”、“世界之窗”的話,自帶的就是ie內核,不用設置。
2、如果是“搜狗”、“傲游3”、“世界之窗極速版”的話,在地址欄右側有“webkit內核”和“ie內核”切換的按鈕。
3、如果是“firefox”或者“chrome”的話,可以下載“ietab”插件,點擊插件圖標切換瀏覽器內核模式,在“ietab”的選項中,可以選擇ie內核的模式,如ie6、ie7、ie8、ie9等。
4、ie瀏覽器10怎么設置兼容
以為例,其ie瀏覽器10設置兼容的方法是:
1、首先在電腦上打開IE瀏覽器,然后再點擊上方菜單欄的工具。
2、接著在彈出的選項內選擇兼容性視圖設置。
3、之后輸入相關網址點擊添加即可。
微軟在MIX11大會上宣布了,在提供下載,也放出了介紹視頻。微軟IE部門企業副總裁迪恩哈查莫維奇()今日在拉斯維加斯召開的Mix開發者大會上展示了第一個平臺預覽版IE10瀏覽器。微軟表示,它打算每隔8到12周將預覽版IE10升級一次,用戶們可登錄網站下載試用預覽版IE10。雖然微軟尚未公布IE10的最終發布日期,而且據說它正在開發,從目前的情況來看,它很可能會在明年的某一時間發布IE10和。
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
