整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
大數據從業者必知必會的Hive SQL調優技巧
摘要:在大數據領域中,Hive SQL被廣泛應用于數據倉庫的數據查詢和分析。然而,由于數據量龐大和復雜的查詢需求,Hive SQL查詢的性能往往不盡人意。本文針對Hive SQL的性能優化進行深入研究,提出了一系列可行的調優方案,并給出了相應的優化案例和優化前后的SQL代碼。通過合理的優化策略和技巧,能夠顯著提升Hive SQL的執行效率和響應速度。
關鍵詞: Hive SQL;性能優化;調優方案;優化案例
1. 引言
隨著大數據時代的到來,數據分析和挖掘變得越來越重要。Hive作為Hadoop生態系統中的數據倉庫工具,扮演著重要的角色。然而,由于數據量龐大和查詢復雜性,Hive SQL查詢的執行效率往往較低。因此,深入了解Hive SQL調優技巧對于數據工程師和數據分析師來說至關重要。
2. 先做個自我反思
很多時候, Hive SQL 運行得慢是由開發人員對于使用的數據了解不夠以及一些不良的使用習慣引起的。
?真的需要掃描這么多分區嗎?
**比如,對于銷售明細事務表來說,掃描一年的分區和掃描一周的分區所帶來的計算、 IO 開銷完全是兩個量級,所耗費的時間肯定也是不同的。作為開發人員,我們需要仔細考慮業務的需求,盡量不要浪費計算和存儲資源。
?習慣使用select *這樣的方式,而不是用到哪些列就指定哪些列嗎?
比如,select coll, col2 from ,另外, where 條件中也盡量添加過濾條件,以去掉無關的數據行,從而減少整個 任務中需要處理、分發的數據量。
?需要計算的指標真的需要從數據倉庫的公共明細層來自行匯總嗎?
是不是數倉團隊開發的公共匯總層已經可以滿足你的需求?對于通用的、管理者駕駛艙相關的指標等通常設計良好的數據倉庫公共層肯定已經包含了,直接使用即可。

3 查詢優化
3.1 盡量原子化操作
盡量避免一個SQL包含復雜邏輯,可以使用中間表來完成復雜的邏輯。建議對作業進行合理拆分,降低作業出問題重跑時資源的浪費和下游時效的影響。
3.2 使用合適的數據類型
選擇合適的數據類型可以減小存儲空間和提高查詢效率。例如,將字符串類型轉換為整型類型可以節省存儲空間并加快查詢速度。
優化案例
優化前:
SELECT * FROM table WHERE age = '30';
優化后:
SELECT * FROM table WHERE age = 30;
3.3 避免全表掃描
盡量避免全表掃描,可以通過WHERE子句篩選出需要的數據行,或者使用LIMIT子句限制返回結果的數量。
反面案例
天天全表掃描計算所有歷史數據。 map數超20萬。
Select * from table where dt<=’{TX_DATE}’
優化案例1
優化前:
--優化前副表的過濾條件寫在where后面,會導致先全表關聯再過濾分區。
select a.* from test1 a left join test2 b on a.uid = b.uid where a.ds='2020-08-10' and b.ds='2020-08-10'
優化后:
select a.* from test1 a left join test2 b on (b.uid is not null and a.uid = b.uid and b.ds='2020-08-10') where a.ds='2020-08-10'
優化案例2
利用max函數取表最大分區,造成全表掃描。
優化前:
Select max(dt) from table
優化后:
使用自定義(show partition 或 hdfs dfs –ls )的方式替代max(dt)
3.4 使用分區
數據分區是一種將數據按照某個字段進行分組存儲的技術,可以有效減少查詢時的數據掃描量。通過分區字段進行數據過濾,可以只對目標分區進行查詢,加快查詢速度。
優化案例
優化前:
SELECT * FROM table WHERE date = '2021-01-01' AND region = 'A';
優化后:
SELECT * FROM table WHERE partition_date = '2021-01-01' AND partition_region = 'A';
反面案例
代碼寫死日期,一次性不合理掃描2年+日志數據。map數超20萬,而且會越來越大,直到跑不出來。
Select * from table where src_mark=’23’ and dt between ‘2020-05-16’ and ‘{TX_DATE}’ and scr_code is not null
3.5 使用索引
在Hive SQL中,可以通過創建索引來加速查詢操作。通過在關鍵字段上創建索引,可以減少數據掃描和過濾的時間,提高查詢性能。
優化案例
優化前:
SELECT * FROM table WHERE region = 'A' AND status = 'ACTIVE';
優化后:
CREATE INDEX idx_region_status ON table (region, status);
SELECT * FROM table WHERE region = 'A' AND status = 'ACTIVE';
3.6 查詢重寫
查詢重寫是一種通過改變查詢語句的結構或使用優化的查詢方式,來改善查詢的性能的技巧。可以通過重寫子查詢、使用JOIN代替IN/EXISTS子查詢等方法來優化查詢。
優化案例
優化前:
SELECT * FROM table1 WHERE id IN (SELECT id FROM table2 WHERE region = 'A');
優化后:
SELECT * FROM table1 t1 JOIN (SELECT id FROM table2 WHERE region = 'A') t2 ON t1.id = t2.id;
3.7 謂詞下推
謂詞下推是一種將過濾條件盡早應用于查詢計劃中的技術(即SQL語句中的WHERE謂詞邏輯都盡可能提前執行),減少下游處理的數據量。通過將過濾條件下推至數據源,可以減少查詢數據量,提升查詢性能。
優化案例
優化前:
select a.*,b.* from a join b on a.name=b.name where a.age>30
優化后:

SELECT a.*, b.* FROM ( SELECT * FROM a WHERE age > 30 ) a JOIN b ON a.name = b.name
3.8 不要用COUNT
COUNT 操作需要用一個Reduce Task來完成,這一個Reduce需要處理的數據量太大,就會導致整個Job很難完成,一般COUNT 使用先GROUP BY再COUNT的方式替換,雖然會多用一個Job來完成,但在數據量大的情況下,這個絕對是值得的。
優化案例
優化前:
select count(distinct uid) from test where ds='2020-08-10' and uid is not null
優化后:
select count(a.uid) from (select uid from test where uid is not null and ds = '2020-08-10' group by uid) a
3.9 使用with as
拖慢hive查詢效率出了join產生的shuffle以外,還有一個就是子查詢,在SQL語句里面盡量減少子查詢。with as是將語句中用到的子查詢事先提取出來(類似臨時表),使整個查詢當中的所有模塊都可以調用該查詢結果。使用with as可以避免Hive對不同部分的相同子查詢進行重復計算。
優化案例
優化前:
select a.* from test1 a left join test2 b on a.uid = b.uid where a.ds='2020-08-10' and b.ds='2020-08-10'
優化后:
with b as select uid from test2 where ds = '2020-08-10' and uid is not null select a.* from test1 a left join b on a.uid = b.uid where a.ds='2020-08-10' and a.uid is not null
3.10 大表Join小表
在編寫具有Join操作的查詢語句時,有一項重要的原則需要遵循:應當將記錄較少的表或子查詢放置在Join操作符的左側。這樣做有助于減少數據量,提高查詢效率,并有效降低內存溢出錯誤的發生概率。
如果未指定MapJoin,或者不符合MapJoin的條件,Hive解析器將會將Join操作轉換成Common Join。這意味著Join操作將在Reduce階段完成,由此可能導致數據傾斜的問題。為了避免這種情況,可以通過使用MapJoin將小表完全加載到內存中,并在Map端執行Join操作,從而避免將Join操作留給Reducer階段處理。這種策略有效地減少了數據傾斜的風險。
優化案例
--設置自動選擇Mapjoin
set hive.auto.convert.join = true; 默認為true
--大表小表的閾值設置(默認25M以下認為是小表):
set hive.mapjoin.smalltable.filesize=25000000;
3.11 大表Join大表
3.11.1 空key過濾
有時候,連接操作超時可能是因為某些key對應的數據量過大。相同key的數據被發送到相同的reducer上,由此導致內存不足。在這種情況下,我們需要仔細分析這些異常的key。通常,這些key對應的數據可能是異常的,因此我們需要在SQL語句中進行適當的過濾。
3.11.2 空key轉換
當某個key為空時,盡管對應的數據很豐富,但并非異常情況。在執行join操作時,這些數據必須包含在結果集中。為實現這一目的,可以考慮將表a中那些key為空的字段賦予隨機值,以確保數據能夠均勻、隨機地分布到不同的reducer上。
3.12 避免笛卡爾積
在執行join操作時,若不添加有效的on條件或者使用無效的on條件,而是采用where條件,可能會面臨關聯列包含大量空值或者重復值的情況。這可能導致Hive只能使用一個reducer來完成操作,從而引發笛卡爾積和數據膨脹問題。因此,在進行join時,務必注意確保使用有效的關聯條件,以免由于數據的空值或重復值而影響操作性能。
優化案例
優化前:
SELECT * FROM A, B;
--在優化前的SQL代碼中,使用了隱式的內連接(JOIN),沒有明確指定連接條件,導致產生了笛卡爾積
優化后;
SELECT * FROM A CROSS JOIN B;
在優化后的SQL代碼中,使用了明確的交叉連接(CROSS JOIN),確保只返回A和B表中的所有組合,而不會產生重復的行。 通過明確指定連接方式,可以避免不必要的笛卡爾積操作,提高查詢效率。
4. 數據加載和轉換
4.1 使用壓縮格式
在數據加載過程中,選擇合適的數據存儲格式(對于結構化數據,可以選擇Parquet或ORC等列式存儲格式;對于非結構化數據,可以選擇或等格式),可以提高查詢性能和減少存儲空間。
優化案例
優化前:
LOAD DATA INPATH '/path/to/data' INTO TABLE table;
優化后:
LOAD DATA INPATH '/path/to/data' INTO TABLE table STORED AS ORC;
4.2 數據轉換和過濾
在數據加載之前,對數據進行轉換和過濾可以減小數據量,并加快查詢速度。例如,可以使用Hive內置函數對數據進行清洗和轉換,以滿足特定的查詢需求。
優化案例
優化前:
SELECT * FROM table WHERE name LIKE '%John%';
優化后:
SELECT * FROM table WHERE name = 'John';
4.3 多次INSERT單次掃描表
默認情況下,Hive會執行多次表掃描。因此,如果要在某張hive表中執行多個操作,建議使用一次掃描并使用該掃描來執行多個操作。
比如將一張表的數據多次查詢出來裝載到另外一張表中。如下面的示例,表是一個分區表,分區字段為dt,如果需要在表中查詢2個特定的分區日期數據,并將記錄裝載到2個不同的表中。
INSERT INTO temp_table_20201115 SELECT * FROM my_table WHERE dt ='2020-11-15';
INSERT INTO temp_table_20201116 SELECT * FROM my_table WHERE dt ='2020-11-16';
在以上查詢中,Hive將掃描表2次,為了避免這種情況,我們可以使用下面的方式:
FROM my_table
INSERT INTO temp_table_20201115 SELECT * WHERE dt ='2020-11-15'
INSERT INTO temp_table_20201116 SELECT * WHERE dt ='2020-11-16'
這樣可以確保只對表執行一次掃描,從而可以大大減少執行的時間和資源。
5. 性能評估和優化
5.1 使用EXPLAIN命令
使用EXPLAIN命令可以分析查詢計劃并評估查詢的性能。通過查看查詢計劃中的資源消耗情況,可以找出潛在的性能問題,并進行相應的優化。
優化案例
優化前:
EXPLAIN SELECT * FROM table WHERE age = 30;
優化后:
EXPLAIN SELECT * FROM table WHERE age = 30 AND partition = 'partition1';
5.2 調整并行度和資源配置
根據集群的配置和資源情況,合理調整Hive查詢的并行度和資源分配,可以提高查詢的并發性和整體性能。通過設置參數hive.exec.值為true,就可以開啟并發執行。不過,在共享集群中,需要注意下,如果job中并行階段增多,那么集群利用率就會增加。建議在數據量大,sql很長的時候使用,數據量小,sql比較的小開啟有可能還不如之前快。
優化案例
優化前:
SET hive.exec.parallel=true;
優化后:
SET hive.exec.parallel=false; SET hive.exec.reducers.max=10;
6. 數據傾斜
任務進度長時間維持在99%(或100%),檢查任務監控頁面后發現僅有少量(1個或幾個)reduce子任務未完成。這些未完成的reduce子任務由于處理的數據量與其他reduce子任務存在顯著差異。具體而言,單一reduce子任務的記錄數與平均記錄數之間存在顯著差異,通常可達到3倍甚至更多。此外,未完成的reduce子任務的最長時長明顯超過了平均時長。主要原因可以歸結為以下幾種:
6.1 空值引發的數據傾斜
在數據倉庫中存在大量空值(NULL)的情況下,導致數據分布不均勻的現象。這種數據傾斜可能會對數據分析和計算產生負面影響。當數據倉庫中某個字段存在大量空值時,這些空值會在數據計算和聚合操作中引起不平衡的情況。例如,在使用聚合函數(如SUM、COUNT、AVG等)對該字段進行計算時,空值并不會被包括在內,導致計算結果與實際情況不符。數據傾斜會導致部分reduce子任務負載過重,而其他reduce子任務負載較輕,從而影響任務的整體性能。這可能導致任務進度長時間維持在99%(或100%),但仍有少量reduce子任務未完成的情況。
優化方案
第一種:可以直接不讓null值參與join操作,即不讓null值有shuffle階段。
第二種:因為null值參與shuffle時的hash結果是一樣的,那么我們可以給null值隨機賦值,這樣它們的hash結果就不一樣,就會進到不同的reduce中。
6.2 不同數據類型引發的數據傾斜
在數據倉庫中,不同數據類型的字段可能具有不同的取值范圍和分布情況。例如,某個字段可能是枚舉類型,只有幾個固定的取值;而另一個字段可能是連續型數值,取值范圍較大。當進行數據計算和聚合操作時,如果不同數據類型的字段在數據分布上存在明顯的差異,就會導致數據傾斜。數據傾斜會導致部分reduce子任務負載過重,而其他reduce子任務負載較輕,從而影響任務的整體性能。這可能導致任務進度長時間維持在99%(或100%),但仍有少量reduce子任務未完成的情況。
優化方案
如果key字段既有string類型也有int類型,默認的hash就都會按int類型來分配,那我們直接把int類型都轉為string就好了,這樣key字段都為string,hash時就按照string類型分配了。
6.3 不可拆分大文件引發的數據傾斜
在Hadoop分布式計算框架中,數據通常會被切分成多個數據塊進行并行處理。然而,當遇到一些無法被切分的大文件時,這些大文件會被作為一個整體分配給一個reduce任務進行處理,而其他reduce任務則可能得到較小的數據量。這導致部分reduce任務負載過重,而其他任務負載較輕,從而影響任務的整體性能。
優化方案
這種數據傾斜問題沒有什么好的解決方案,只能將使用GZIP壓縮等不支持文件分割的文件轉為bzip和zip等支持文件分割的壓縮方式。
所以,我們在對文件進行壓縮時,為避免因不可拆分大文件而引發數據讀取的傾斜,在數據壓縮的時候可以采用bzip2和Zip等支持文件分割的壓縮算法。
6.4 數據膨脹引發的數據傾斜
數據膨脹通常是由于某些數據在倉庫中存在大量冗余、重復或者拆分產生的。當這些數據被用于計算和聚合操作時,會導致部分reduce子任務負載過重,而其他reduce子任務負載較輕,從而影響任務的整體性能。
優化方案
在Hive中可以通過參數
hive.new.job..set. 配置的方式自動控制作業的拆解,該參數默認值是30。表示針對 sets/rollups/cubes這類多維聚合的操作,如果最后拆解的鍵組合大于該值,會啟用新的任務去處理大于該值之外的組合。如果在處理數據時,某個分組聚合的列有較大的傾斜,可以適當調小該值。
6.5 表連接時引發的數據傾斜
在數據倉庫中,表連接是常用的操作,用于將不同表中的數據進行關聯和合并。然而,當連接鍵在不同表中的數據分布不均勻時,就會導致連接結果中某些連接鍵對應的數據量遠大于其他連接鍵的數據量。這會導致部分reduce任務負載過重,而其他任務負載較輕,從而影響任務的整體性能。
優化方案
通常做法是將傾斜的數據存到分布式緩存中,分發到各個Map任務所在節點。在Map階段完成join操作,即MapJoin,這避免了 Shuffle,從而避免了數據傾斜。
6.6 確實無法減少數據量引發的數據傾斜
在某些情況下,數據的數量本身就非常龐大,例如某些業務場景中的大數據集,或者歷史數據的積累等。在這種情況下,即使采取了數據預處理、數據分區等措施,也無法減少數據的數量。
優化方案
這類問題最直接的方式就是調整reduce所執行的內存大小。
調整reduce的內存大小使用
.reduce.memory.mb這個配置。
7. 合并小文件
在HDFS中,每個小文件對象約占150字節的元數據空間,如果有大量的小文件存在,將會占用大量的內存資源。這將嚴重限制節點的內存容量,進而影響整個集群的擴展能力。從Hive的角度來看,小文件會導致產生大量的Map任務,每個Map任務都需要啟動一個獨立的JVM來執行。這些任務的初始化、啟動和執行會消耗大量的計算資源,嚴重影響性能,因為每個小文件都需要進行一次磁盤IO操作。
因此,我強烈建議避免使用包含大量小文件的數據源。 相反,我們應該進行小文件合并操作,以減少查詢過程中的磁盤IO次數,從而提高查詢效率。通過合并小文件,我們可以將多個小文件合并成一個較大的文件,從而減少對磁盤的IO訪問次數。這樣可以降低系統資源的消耗,提高查詢性能。
因此,在構建數據倉庫時,應該盡可能使用較大的文件來存儲數據,避免大量小文件的產生。如果已經存在大量小文件,可以考慮進行小文件合并操作,以優化數據存儲和查詢性能。這樣可以提高Hive查詢的效率,減少資源的浪費,并保證系統的穩定性和可擴展性。
7.1 Hive引擎合并小文件參數
--是否和并Map輸出文件,默認true
set hive.merge.mapfiles = true;
--是否合并 Reduce 輸出文件,默認false
set hive.merge.mapredfiles = true;
--合并文件的大小,默認字節
set hive.merge.size.per.task = 256000000;
--當輸出文件的平均大小小于該值時,啟動一個獨立的map-reduce任務進行文件merge,默認字節
set hive.merge.smallfiles.avgsize = 256000000;
7.2 Spark引擎合并小文件參數,所以盡量將MR切換成Spark
--是否合并小文件,默認true
conf spark.sql.hive.mergeFiles=true;
8. 結論
本論文介紹了大數據從業者必備的Hive SQL調優技巧,包括查詢優化、數據分區和索引、數據加載和轉換等方面。通過深入理解Hive SQL語言和優化策略,開發人員可以提升查詢效率和性能。通過優化案例和優化前后的SQL代碼,展示了每種優化方案的實際應用效果。****
附:實踐案例
一、背景
某公司的線上平臺每天產生大量的用戶數據,包括用戶行為、訂單信息等。為了更好地分析用戶行為和業務趨勢,我們需要對數據進行復雜的查詢操作。原始的Hive SQL語句在執行時存在性能瓶頸,因此我們決定對其進行優化。
二、原始SQL語句
原始的Hive SQL語句如下:
SELECT * FROM user_data WHERE user_id IN (SELECT user_id FROM order_data WHERE order_date >= '2022-01-01')
這個查詢語句的目的是從表中選取所有在表中最近一個月有訂單的用戶數據。由于表和表的數據量都很大,這個查詢語句執行時間較長,存在性能瓶頸。
三、優化策略
針對原始SQL語句的性能瓶頸,我們采取了以下優化策略:
使用Spark計算引擎:Spark是一種高效的分布式計算框架,可以與Hive SQL集成使用來提高查詢效率。我們將使用Spark計算引擎來執行查詢。
使用JOIN操作:將兩個表通過JOIN操作連接起來,可以減少數據的傳輸和計算開銷。我們將使用JOIN操作來連接表和表。
使用過濾條件:在查詢過程中,使用過濾條件可以減少數據的處理量。我們將使用過濾條件來篩選出符合條件的用戶數據。
四、優化后的SQL語句
基于上述優化策略,我們優化后的Hive SQL語句如下:
SELECT u.* FROM user_data u JOIN (SELECT user_id FROM order_data WHERE order_date >= '2022-01-01') o ON u.user_id = o.user_id
這個查詢語句使用了JOIN操作將表和子查詢結果連接起來,并通過過濾條件篩選出符合條件的用戶數據。同時,我們使用了Spark計算引擎來執行查詢。
五、性能對比
我們對優化前后的SQL語句進行了性能對比。以下是性能對比的結果:
執行時間:優化后的SQL語句執行時間比原始SQL語句減少了約50%。
數據傳輸量:優化后的SQL語句減少了數據的傳輸量,提高了數據處理的效率。
內存消耗:優化后的SQL語句使用了Spark計算引擎,可以更好地利用內存資源,提高了查詢性能。
通過對比可以看出,優化后的SQL語句在執行時間、數據傳輸量和內存消耗等方面都取得了顯著的提升。
i.MX6ULL開發板-Buildroot制作交叉編譯器
前言
文章基于HD-IMX6ULL-MB 系列開發板測試驗證,該開發板由武漢芯路遙科技有限公司與武漢萬象奧科電子有限公司合作推出。此開發板基于 NXP iMX6ULL 系列 Cortex-A7 高性能處理器設計,適用于快速開發一系列具有創新性的產品如人機界面工業 4.0 掃描儀、車載終端以及便攜式醫療設備。

1. 制作交叉編譯器
在前面我們提到,如果想要自己制作交叉編譯器的話,通常會用到兩個工具,分別是 -NG 和 。但需要了解的是制作交叉編譯器只是嵌入式開發的第一步,后面我們還需要使用交叉編譯器來移植 、linux kernel 以及制作根文件系統 rootfs,之后還會用它來交叉編譯各種所需要的應用程序。其中 -NG 只是制作了一個交叉編譯器,而如果你希望一鍵完成這所有的事情, 則可以使用 。
如果你是一個嵌入式軟件工程師,那你有必要要知道是什么。這個工具除了可以制 作交叉編譯器以外,還提供了一種更加高效的管理方法,它把,linux,應用程序和rootfs集 成在一起,可以非常方便的去定制,管理,編譯和組裝一個自己需要的,針對自己的設備的一個完整的 軟件系統,這樣我們可以利用針對自己的嵌入式設備開發完整的BSP和SDK。
接下來我們將介紹如何使用 來制作交叉編譯器,同時生成一個開發板可以使用的根文件系統。需要注意的是,因為 Linux 內核 和 u-boot 今后需要自己針對開發板做移植修改,所以這里將不編譯 Linux內核 和 u-boot 程序。
1. 介紹
官網首頁對的定義,和特點有非常明確的介紹: h ttps:/// 。

這里,我們從的官方下載地址下載當前的最新長期支持版本 -2021.02.7 并解壓縮。
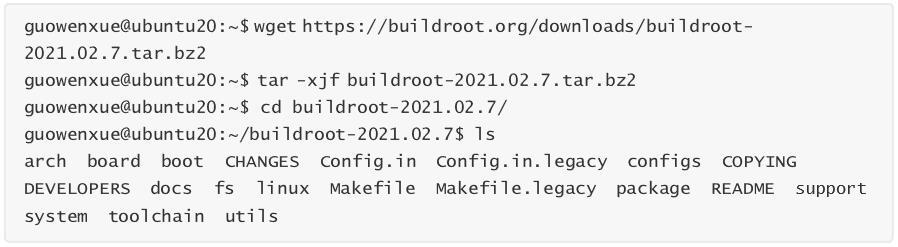
整個是由(*.mk)腳本和Kconfig(Config.in)配置文件構成的,因此可以像配置Linux內 核一樣執行make 進行配置,編譯出一個完整的、可以直接燒寫到機器上運行的Linux系統文件(包含、kernel、rootfs以及rootfs中的各種庫和應用程序)。而構建開源軟件包的流程, 工作流大致如下:
構建每個軟件包的工作流幾乎是相同的,主要就是把這些重復操作自動化,用戶只需勾選上所 需軟件包,便自動完成以上所有操作。其次,U-boot、Linux Kernel的編譯工作流的差不多,只是配置的自定義參數更多,在設置好了,也就一并生成。
1. 配置
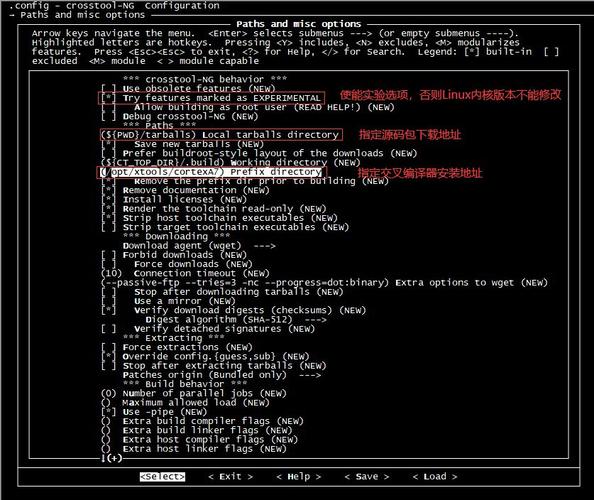
在 源碼路徑下,有很多參考的示例配置,其中就包含有 的參考配置。我們沒有必要所有的選項都自己從0開始配置,接下來我們將在它的基礎上來修改。

如果是使用 遠程登錄到Linux服務器上操作的話,需要 export TERM=vt100 命令配置TERM 環境變量,否則接下來的配置可能不能輸入。接下來再執行 make 對交叉編譯器制作進行配置。
下面是 的配置界面,接下來我們將對齊進行配置。在配置的過程中:
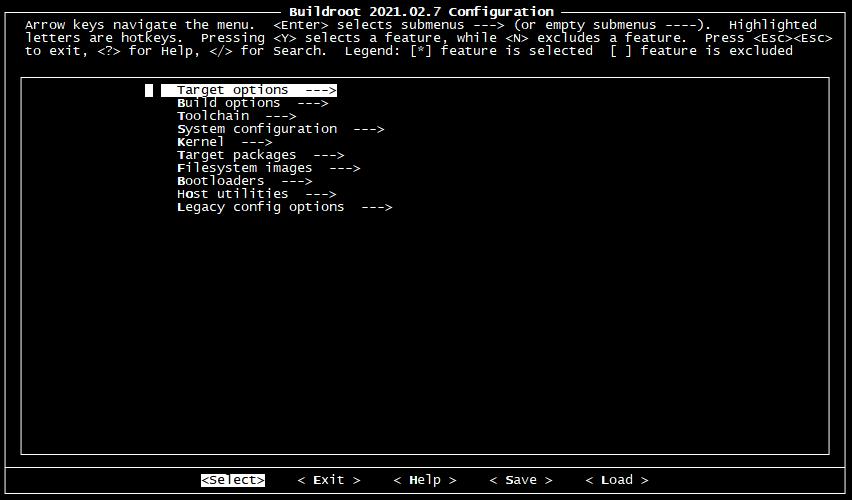
在 Target options 選項中 ,這里配置了交叉編譯器的體系架構信息。因為我們的開發板所有的處理器
i.MX6ULL 是采樣 Cortex-A7架構,帶有 NEON 浮點運算,所以這里做如下的默認配置。
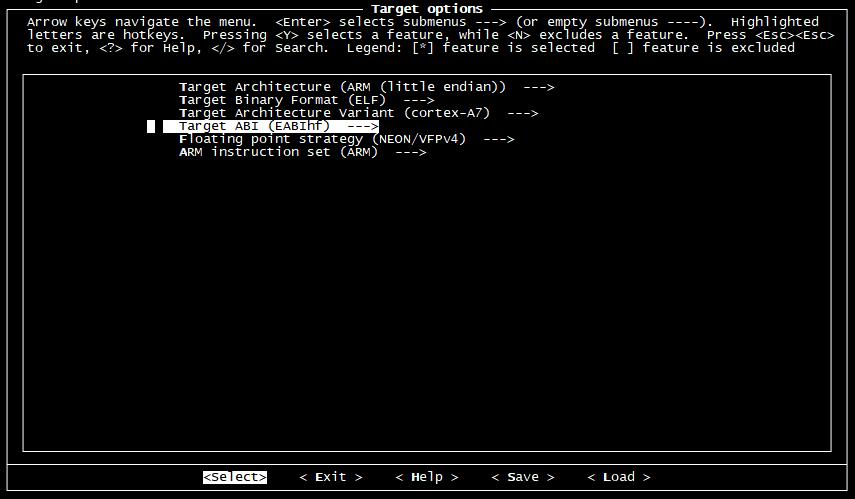

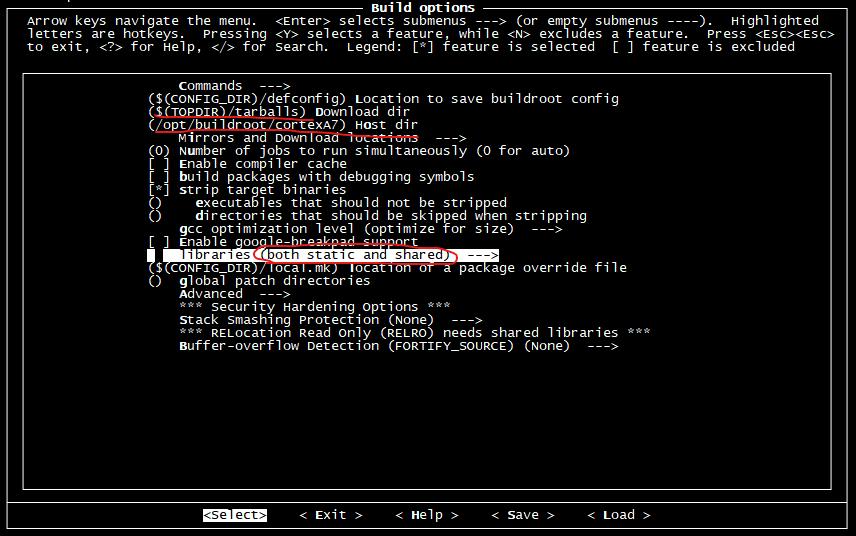
在 Build options 選項中 ,這里主要修改一下:
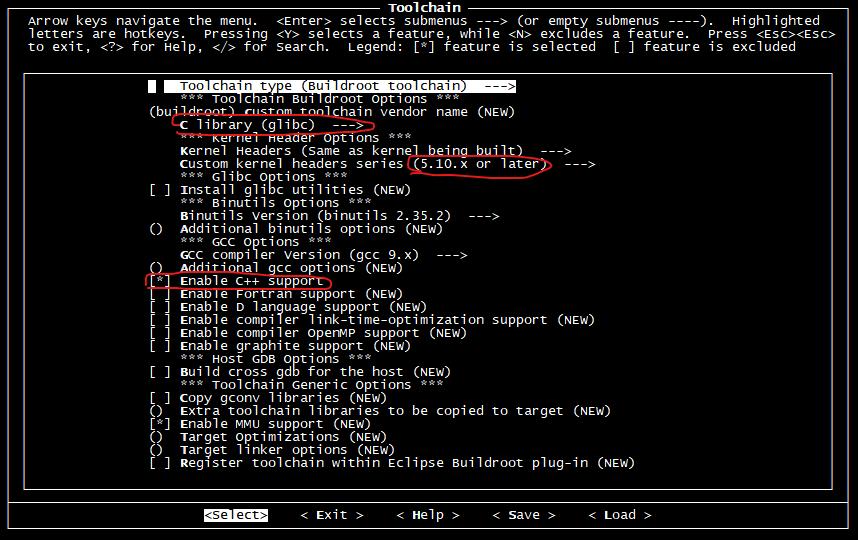
在 選項中,這里做如下修改:
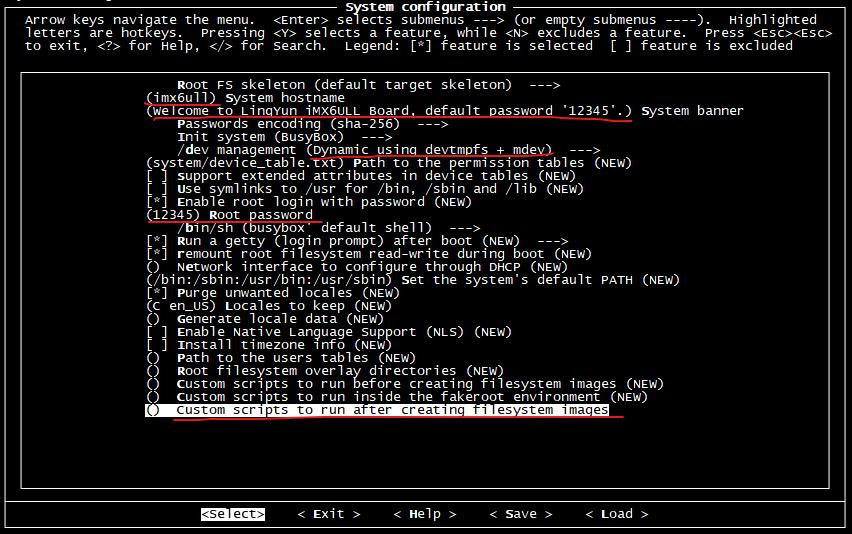
System 選項中配置了根文件系統的相關信息,我們做如下修改:
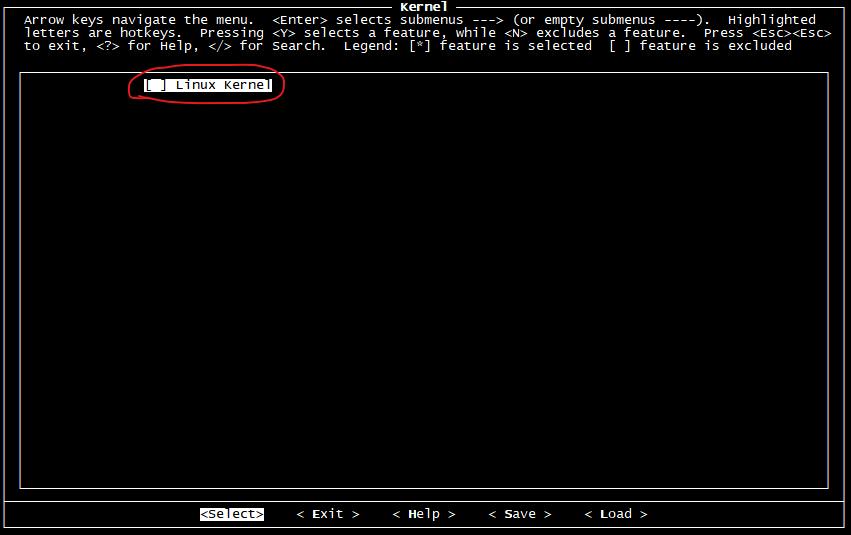
Kernel 選項主要是Linux內核的編譯配置,今后我們將會自己移植并編譯Linux內核,所以這里不要選擇。
Target 選項這里有大量的應用程序或開源庫編譯選項,如果想制作到根文件系統樹中的話, 這里可以做相應的選擇。
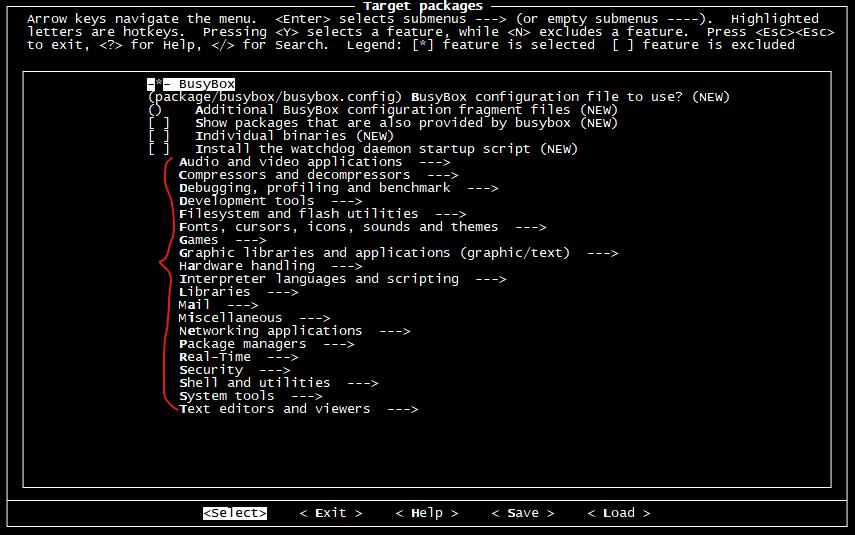
下面是一些建議可以選擇的軟件包:





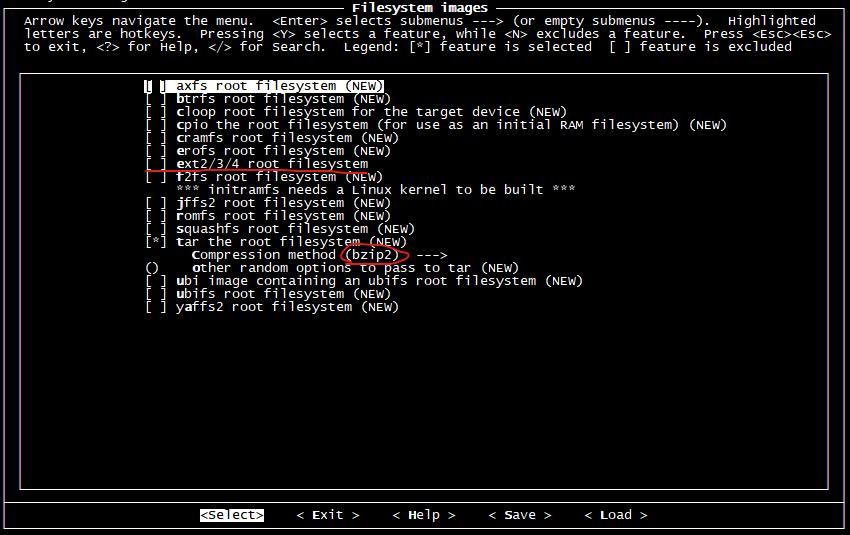
images 選項指定生成根文件系統鏡像的類型,因為我們將來將會自己制作系統鏡像,所以這里不需要生成。只需要將根文件系統樹打包并使用 bzip2 壓縮即可。
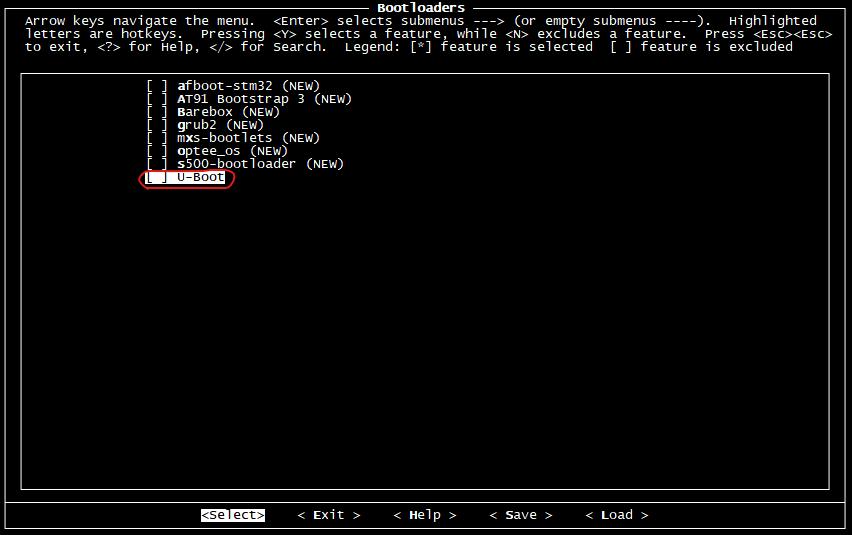
選項主要是u-boot的編譯配置,今后我們將會自己移植并編譯U-boot,所以這里不要選擇。
Host 是在編譯 過程中,X86主機上所依賴的一些工具。可以進去把一些能取消的都取消,從而節省編譯時間;
Legacy config options 是一些過期作廢的軟件包,一般都不需要;
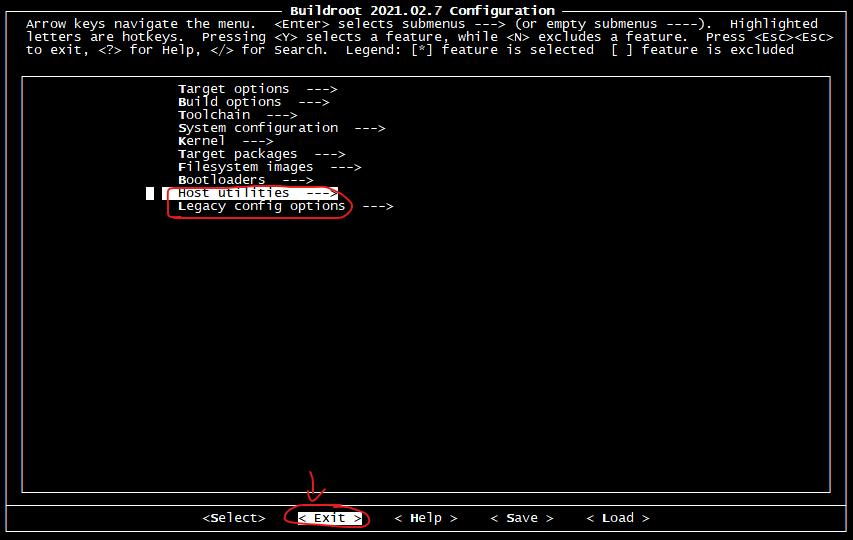
配置完成之后,選擇 < Exit > 退出并保存該配置,這些配置將會保存在當前路徑下的 .config 隱藏文件里。之后的編譯過程將根據這里面的配置,選擇下載、編譯相關程序或代碼。
1. 編譯
首先創建交叉編譯器的安裝路徑,注意制作交叉編譯器別用 root 賬號來完成,否則小心破壞自己的
Linux系統。

接下來我們就開始交叉編譯的編譯制作過程,這個過程的時間依賴PC的性能和所選擇的選項多少。我的
Linux服務器處理器是Intel(R) Xeon(R) CPU E31235 @ 3.20GHz,4核8線程,所以我這里使用 make -j8
命令用8個進程同時編譯。
編譯成功完成之后,輸出如下:
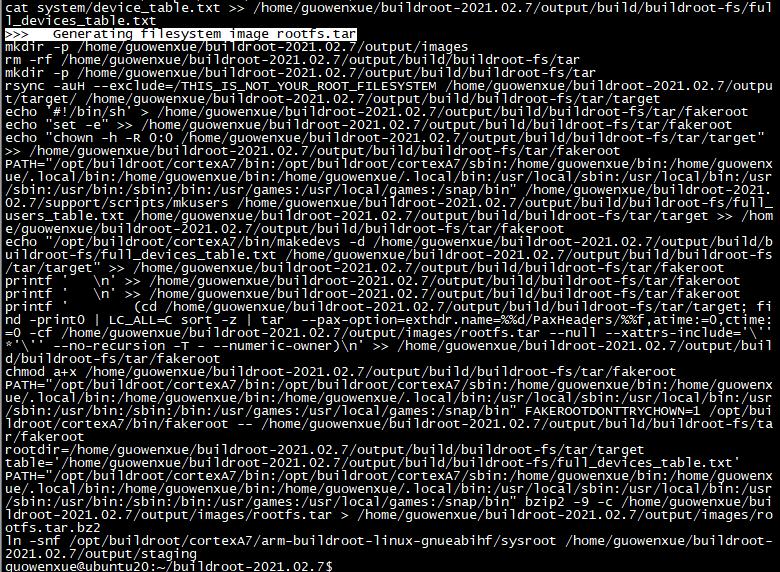
編譯過程中 下載的源碼包 將會放到 文件夾下:


編譯生成的 根文件系統樹 將會放到 output/images/ 文件夾下:

編譯生成的 交叉編譯器 將會放到 /opt// 路徑下:

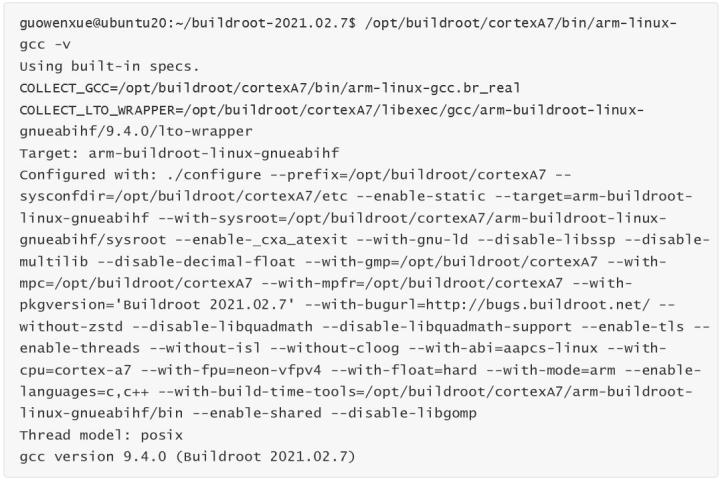
我們可以使用下面命令查看制作好的交叉編譯器相關版本信息:
1.4 測試
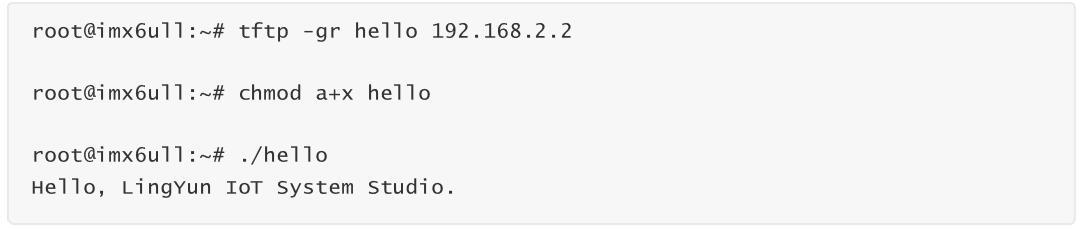
接下來我們使用制作好的交叉編譯器,交叉編譯之前寫好的 hello.c 測試程序,并放到 ARM 開發板上運行測試。需要注意的是因為新制作的交叉編譯器跟開發板上運行的C運行庫版本不一致,這里必須加上 -static 進行靜態鏈接,這樣編譯生成的程序才能在開發板上運行。

ARM 開發板上下載運行測試:
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
