整合營(yíng)銷服務(wù)商
電腦端+手機(jī)端+微信端=數(shù)據(jù)同步管理
免費(fèi)咨詢熱線:

電腦端+手機(jī)端+微信端=數(shù)據(jù)同步管理
免費(fèi)咨詢熱線:
除了字典中包含的由 注釋的首字母縮寫(xiě)詞之外,還可以在每個(gè)文檔的基礎(chǔ)上檢測(cè)到新穎的首字母縮寫(xiě)詞聲明。當(dāng)檢測(cè)到首字母縮寫(xiě)詞定義(形式為“物種(首字母縮略詞)”時(shí),其中物種在字典中,首字母縮寫(xiě)詞是大寫(xiě)字母、數(shù)字或連字符的序列),該首字母縮寫(xiě)詞的所有后續(xù)出現(xiàn)也會(huì)在文檔中標(biāo)記。
刪除常用英語(yǔ)單詞
基于一個(gè)簡(jiǎn)單的物種名稱列表,這些物種名稱在不提及物種時(shí)通常出現(xiàn)在英語(yǔ)中(參見(jiàn)附加文件3),我們刪除了列表中包含物種術(shù)語(yǔ)組合的任何提及 . 這消除了“spot”(對(duì)于 )和“permit”(對(duì)于 )等同義詞,并大大減少了系統(tǒng)產(chǎn)生的誤報(bào)數(shù)量。
為模棱兩可的提及分配概率
最后,任何仍然模棱兩可的提及都被分配了提及特定物種的可能性的概率。模糊提及的概率基于所有 MEDLINE 和 PubMed Central 全文文檔的開(kāi)放訪問(wèn)子集中所涉及物種的明確提及的相對(duì)頻率。首字母縮寫(xiě)詞的概率基于 檢測(cè)到的首字母縮寫(xiě)詞定義的相對(duì)頻率(見(jiàn)上文)。例如,對(duì)于模棱兩可的提及“C. elegans”,出現(xiàn)秀麗隱桿線蟲(chóng)的概率會(huì)非常高,而出現(xiàn)Crella elegans的概率會(huì)很高會(huì)低很多。對(duì)于首字母縮略詞“HIV”(可能同時(shí)指“人類免疫缺陷病毒”,更不常見(jiàn)的是“希波克拉底無(wú)關(guān)變量”),它指代“人類免疫缺陷病毒”的可能性非常高。
這些概率啟用了另一種啟發(fā)式消歧形式:在模棱兩可的提及具有高于給定截止值(例如 99%)的概率的物種替代的情況下,提及可以完全消除該物種的歧義(例如術(shù)語(yǔ)“C. elegans”可以被消除為 elegans)。同樣,如果所有與物種相關(guān)的提及概率之和小于給定閾值(例如 1%),則可以刪除提及;這可能發(fā)生在首字母縮略詞中,在 99% 以上的情況下,首字母縮略詞用于非物種術(shù)語(yǔ)。這些級(jí)別在準(zhǔn)確性和模糊性最小化之間進(jìn)行了權(quán)衡,并且可以在標(biāo)記后根據(jù)用戶的個(gè)人需求進(jìn)行調(diào)整。
輸入和輸出格式
能夠處理各種文檔 XML 格式,包括 MEDLINE XML、PMC XML、Biomed Central XML和 Open Text Mining XML。此外,它還可以處理來(lái)自本地存儲(chǔ)文件和遠(yuǎn)程數(shù)據(jù)庫(kù)服務(wù)器的純文本文檔。物種名稱識(shí)別結(jié)果可以存儲(chǔ)到基于對(duì)峙的制表符分隔值文件、XML 文檔、HTML 文檔(用于結(jié)果的簡(jiǎn)單可視化)和遠(yuǎn)程 MySQL 數(shù)據(jù)庫(kù)表中。
用于物種標(biāo)記的文檔集
在整個(gè)工作中,使用了三個(gè)不同的文檔集來(lái)識(shí)別和規(guī)范物種名稱。對(duì)于所有集合,2008 年之后發(fā)布的任何文檔都被刪除,以創(chuàng)建固定和可重復(fù)的文檔集合,并避免在項(xiàng)目過(guò)程中因數(shù)據(jù)庫(kù)記錄更新而可能出現(xiàn)的差異。
醫(yī)療線
MEDLINE 是 PubMed 文章摘要的主要數(shù)據(jù)庫(kù),包含超過(guò) 1800 萬(wàn)條條目。然而,許多條目實(shí)際上并不包含任何摘要。如果僅計(jì)算截至 2008 年底發(fā)表的包含摘要的條目,則文件數(shù)量剛剛超過(guò) 990 萬(wàn)份。
PubMed Central 開(kāi)放獲取子集
PMC 免費(fèi)提供超過(guò)一百萬(wàn)篇全文文章。不幸的是,其中只有大約 10%(截至 2008 年底發(fā)布了 105,106 篇)是真正的開(kāi)放訪問(wèn)并可用于不受限制的文本挖掘。此 PMC 的開(kāi)放存取 (OA) 子集中的文章在此稱為“PMC OA”。PMC OA 中的大部分文章都是基于 XML 文件,但有些是通過(guò)掃描非數(shù)字文章(29,036 個(gè)文檔)的光學(xué)字符識(shí)別(OCR)創(chuàng)建的,還有一些是通過(guò)轉(zhuǎn)換便攜式文檔格式(PDF ) 文檔到文本(9,287 個(gè)文檔)。我們注意到,對(duì)于使用 OCR 或 pdf 到文本軟件生成的 PMC OA 文檔,不會(huì)從這些文檔中刪除參考。正因?yàn)槿绱耍霈F(xiàn)在參考標(biāo)題中的物種名稱可能會(huì)被標(biāo)記。對(duì)于所有其他文件(MEDLINE、即不處理參考標(biāo)題)。
PMC OA 的摘要
PMC OA 集中所有文章的摘要形成一個(gè)稱為“PMC OA abs”的集。PMC OA 摘要是從 PMC OA XML 文件的摘要部分獲得的,或者如果 XML 文件中不存在這樣的部分,則從相應(yīng)的 MEDLINE 條目獲得(當(dāng)文章是通過(guò) OCR 或 pdf 到文本工具生成時(shí)會(huì)發(fā)生這種情況) . PMC OA 摘要包含 88,962 篇文檔,明顯少于 PMC OA 中的文檔數(shù)量(105,106 篇)。這是因?yàn)椴⒎撬?PMC 文章都被 MEDLINE 索引,因此一些 OCR 或 pdf 轉(zhuǎn)文本文檔沒(méi)有對(duì)應(yīng)的 MEDLINE 條目,使得準(zhǔn)確提取摘要不可行。在 88,962 篇摘要中,有 65,739 篇(74%)是從 XML 文檔中提取的,其余部分是從相應(yīng)的 MEDLINE 文檔中提取的。
PMC OA 全文文檔集的劃分
如上一節(jié)所述,不可能可靠地提取 PubMed Central 中大約五分之一的全文文章的摘要,因?yàn)樗鼈冊(cè)?PMC XML 或相應(yīng)的 MEDLINE 條目中沒(méi)有摘要部分。我們選擇不從我們的分析中刪除這些全文文章,因?yàn)樗鼈儼?PubMed Central 中的大量文檔子集,并且它們的排除可能會(huì)使我們的結(jié)果產(chǎn)生偏差。但是,它們的包含使得基于 PMC OA 摘要和所有 PMC OA 全文文檔的結(jié)果的直接比較變得困難,因?yàn)?PMC OA 全文集中存在一些文檔,而 PMC OA 摘要集中缺少這些文檔。為了在文檔層面解決這個(gè)問(wèn)題,我們創(chuàng)建了“PMC OA full (abs)”集,其中包含可以提取摘要的 88,962 個(gè)全文文檔,允許直接比較完全相同文章的全文文檔和摘要。不幸的是,該文檔集仍然不允許在摘要和全文之間進(jìn)行直接提及級(jí)別的比較,因?yàn)閬?lái)自 MEDLINE 條目的偏移坐標(biāo)和 PMC OA 全文文檔不兼容。因此,我們創(chuàng)建了“PMC OA full (xml)”集,該集僅包含 65,739 個(gè)全文文檔,其中可以從相應(yīng)的 PMC XML 文件中提取摘要。使用此 PMC OA 全文 XML 集,還可以在相同偏移坐標(biāo)上對(duì)相同文檔集執(zhí)行提及級(jí)別比較。我們注意到“PMC OA”是指完整的 105,106 個(gè)全文文檔集,我們也可以將其表示為“PMC OA full (all)”。
用于評(píng)估的文檔集
目前,不存在專門(mén)針對(duì)物種提及進(jìn)行注釋的生物醫(yī)學(xué)文檔的開(kāi)放訪問(wèn)語(yǔ)料庫(kù)。因此,我們創(chuàng)建了許多自動(dòng)生成的評(píng)估集,以分析 和其他物種名稱標(biāo)記軟件的準(zhǔn)確性。由于它們所基于的數(shù)據(jù)的性質(zhì),許多這些評(píng)估集只能在文檔級(jí)別進(jìn)行分析。此外,這些自動(dòng)生成的評(píng)估集都不是基于專門(mén)為注釋物種提及而創(chuàng)建的數(shù)據(jù)。正因?yàn)槿绱耍覀儎?chuàng)建了一個(gè)為物種提及手動(dòng)注釋的全文文章的評(píng)估集。每個(gè)評(píng)估集覆蓋的文檔、物種和標(biāo)簽的數(shù)量如表1所示完整的手動(dòng)注釋文檔可以在項(xiàng)目網(wǎng)頁(yè)上找到。
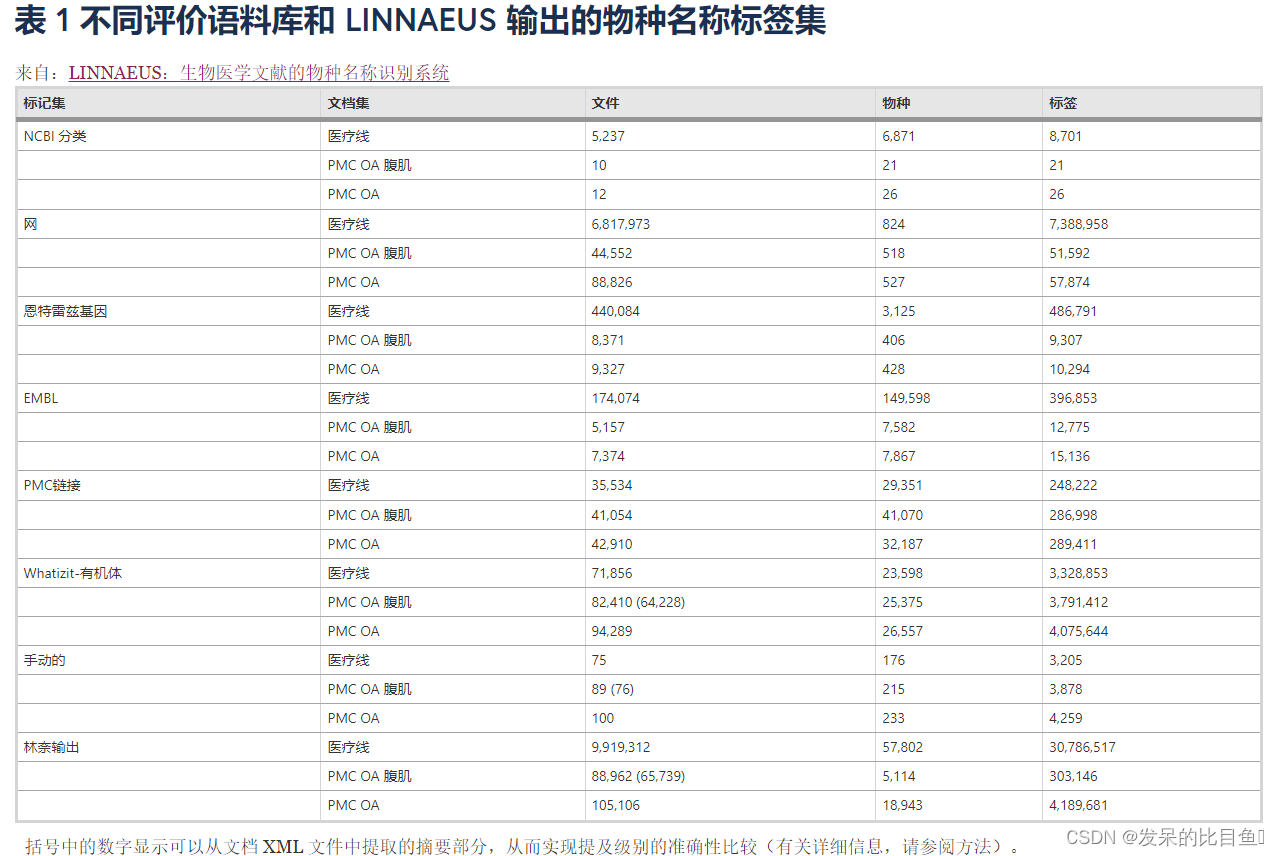
NCBI 分類引文

NCBI 分類中的一些物種條目包含對(duì)討論該物種的研究文章的引用。對(duì)于這些文件,我們假設(shè)該物種最有可能在文章的某處被提及,從而使相對(duì)回憶成為一種有用的衡量標(biāo)準(zhǔn)。NCBI 分類引文于 2009 年 6 月 1 日下載。
醫(yī)學(xué)主題詞條
MEDLINE 中的每篇文章都有相關(guān)的 MeSH 術(shù)語(yǔ),指定文章中討論的主題。這些術(shù)語(yǔ)的一個(gè)子集與物種有關(guān),并且可以通過(guò)統(tǒng)一醫(yī)學(xué)語(yǔ)言系統(tǒng) (UMLS) 映射到 NCBI 分類物種條目。然而,由 MeSH 術(shù)語(yǔ)表示的物種數(shù)量是有限的。總共只有 1,283 個(gè)物種的 MeSH 術(shù)語(yǔ),在 MEDLINE 的 MeSH 標(biāo)簽中實(shí)際出現(xiàn)的物種只有 824 個(gè)。此外,賦予文章的 MeSH 術(shù)語(yǔ)并不能保證該術(shù)語(yǔ)在文檔中明確提及。此外,預(yù)計(jì)文檔中提及的總物種中只有一小部分會(huì)在 MeSH 標(biāo)簽中表示(只有所謂的焦點(diǎn)物種),導(dǎo)致使用該語(yǔ)料庫(kù)的精度估計(jì)不如召回信息量大。
Entrez 基因條目
MEDLINE 中的每篇文章都有相關(guān)的 MeSH 術(shù)語(yǔ),指定文章中討論的主題。這些術(shù)語(yǔ)的一個(gè)子集與物種有關(guān),并且可以通過(guò)統(tǒng)一醫(yī)學(xué)語(yǔ)言系統(tǒng) (UMLS) 映射到 NCBI 分類物種條目。然而,由 MeSH 術(shù)語(yǔ)表示的物種數(shù)量是有限的。總共只有 1,283 個(gè)物種的 MeSH 術(shù)語(yǔ),在 MEDLINE 的 MeSH 標(biāo)簽中實(shí)際出現(xiàn)的物種只有 824 個(gè)。此外,賦予文章的 MeSH 術(shù)語(yǔ)并不能保證該術(shù)語(yǔ)在文檔中明確提及。此外,預(yù)計(jì)文檔中提及的總物種中只有一小部分會(huì)在 MeSH 標(biāo)簽中表示(只有所謂的焦點(diǎn)物種),導(dǎo)致使用該語(yǔ)料庫(kù)的精度估計(jì)不如召回信息量大。
EMBL 記錄
與 Entrez 基因記錄類似,許多 EMBL序列記錄還包含有關(guān)該序列來(lái)自哪個(gè)物種以及該序列是在哪篇文章中報(bào)道的信息。假設(shè)在報(bào)告核苷酸序列的論文中明確提到了物種,這可以提取物種-文章映射。然而,與 Entrez 基因集一樣,這并不能保證,除了具有報(bào)告序列的物種之外,討論的任何物種都不會(huì)出現(xiàn)在評(píng)估集中(再次導(dǎo)致精確測(cè)量無(wú)信息)。該評(píng)估集使用了 EMBL 的 r98 版本。
PubMed 中央鏈接
盡管沒(méi)有在任何出版物中描述,NCBI 對(duì) PMC 中包含的全文文章進(jìn)行物種識(shí)別文本挖掘。這些分類“鏈接”可以在查看 PMC 上的文章時(shí)訪問(wèn),也可以通過(guò) NCBI e-utils Web 服務(wù)下載。通過(guò)下載這些鏈接,可以創(chuàng)建與召回率和精度相關(guān)的評(píng)估集(盡管僅在文檔級(jí)別)。PMC 鏈接數(shù)據(jù)于 2009 年 6 月 1 日下載。
為了評(píng)估提及級(jí)別的準(zhǔn)確性并將 與另一個(gè)物種名稱識(shí)別系統(tǒng)進(jìn)行基準(zhǔn)比較,PMC OA 集中的所有文檔都通過(guò) Web 服務(wù)管道發(fā)送。不幸的是, Web 服務(wù)無(wú)法處理大約 10% 的 PMC OA 文檔(參見(jiàn)表1),因此無(wú)法進(jìn)行比較。 標(biāo)記于 2009 年 6 月 25 日?qǐng)?zhí)行。
人工標(biāo)注的金標(biāo)準(zhǔn)語(yǔ)料庫(kù)
由于所有前面描述的評(píng)估集都受到它們沒(méi)有專門(mén)為物種名稱注釋的事實(shí)的限制,因此很明顯需要這樣一個(gè)集來(lái)測(cè)量 的真實(shí)準(zhǔn)確性。因?yàn)闆](méi)有這樣的評(píng)估集可用,所以從 PMC OA 文檔集中隨機(jī)選擇了 100 個(gè)全文文檔并為物種提及進(jìn)行了注釋。由于這項(xiàng)工作的重點(diǎn)是物種而不是屬或其他更高階的分類單位,因此語(yǔ)料庫(kù)僅針對(duì)物種進(jìn)行了注釋(除了在提及物種時(shí)錯(cuò)誤地使用了屬名的情況)。
所有提及的物種術(shù)語(yǔ)均手動(dòng)注釋并標(biāo)準(zhǔn)化為預(yù)期物種的 NCBI 分類 ID,但作者未提及該物種的術(shù)語(yǔ)除外。一個(gè)常見(jiàn)的例子是“Fisher 精確檢驗(yàn)”(“Fisher”是Martes 的同義詞,但在這種情況下指的是發(fā)明統(tǒng)計(jì)檢驗(yàn)的 Ronald Aylmer Fisher 爵士)。在 NCBI 分類中不存在物種 ID 的情況下(主要發(fā)生在特定物種菌株中),它們的物種 ID 為 0(在 NCBI 分類中不使用)。
帶注釋的提及也被分配到以下類別,這些類別表明提及的特定特征,可用于評(píng)估分析:
(一)詞匯類別:
提及可能屬于多個(gè)類別(例如,它可能既用作修飾符又可能拼寫(xiě)錯(cuò)誤),或者根本不屬于任何類別(即只是普通提及,這是最常見(jiàn)的情況)。表2顯示了與每個(gè)類別相關(guān)的物種標(biāo)簽數(shù)量的摘要。這些類別可以深入了解物種名稱在文獻(xiàn)中拼寫(xiě)錯(cuò)誤或使用不正確的頻率。它們還可以對(duì) 或針對(duì)該語(yǔ)料庫(kù)評(píng)估的任何其他軟件所做的任何預(yù)測(cè)錯(cuò)誤進(jìn)行更深入的分析。在該語(yǔ)料庫(kù)中注釋的 4259 個(gè)物種中,72% (3065) 是常用名稱,這加強(qiáng)了在處理生物醫(yī)學(xué)研究文章時(shí)能夠準(zhǔn)確識(shí)別常用名稱的重要性。
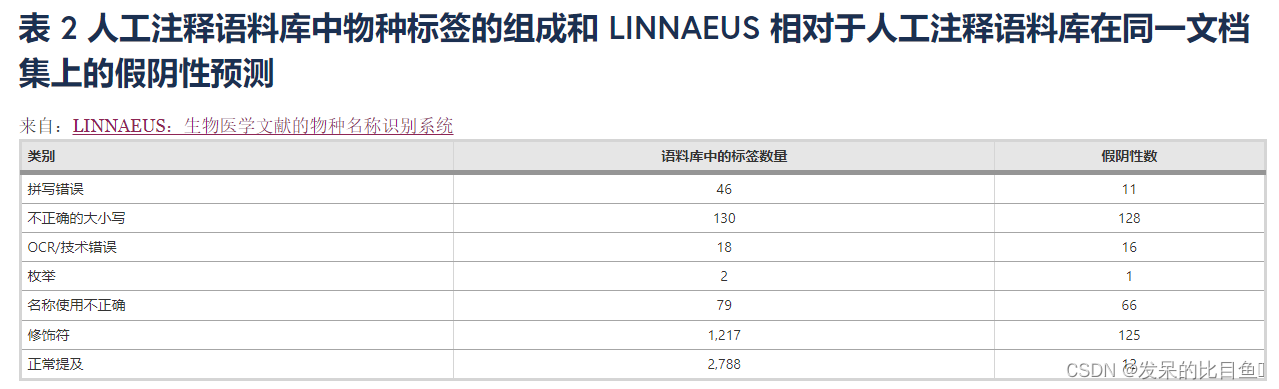
為了估計(jì)手動(dòng)注釋的可靠性,10% 的語(yǔ)料庫(kù)(10 個(gè)文檔)也由第二個(gè)注釋器注釋,并計(jì)算了注釋器間協(xié)議 (IAA)。總共有 406 個(gè)物種提及在 10 個(gè)文件中由至少一個(gè)注釋者注釋。在這 406 次提及中,368 次被兩個(gè)注釋器(提及位置和物種標(biāo)識(shí)符)相同地注釋。Cohen 對(duì)注釋者間一致性的 k 度量 [ 53 ] 計(jì)算為 k = 0.89。IAA 分析的詳細(xì)信息可在附加文件4中找到。
績(jī)效評(píng)估
將 生產(chǎn)的標(biāo)簽與評(píng)估參考集中的標(biāo)簽進(jìn)行比較,以確定系統(tǒng)的性能。如果特定標(biāo)簽同時(shí)出現(xiàn)在 集和參考集中,則稱為真陽(yáng)性(TP);如果它僅出現(xiàn)在 集中,則稱為誤報(bào) (FP);如果它僅出現(xiàn)在參考集中,則稱為假陰性(FN)。這在文檔級(jí)別(不考慮文檔中標(biāo)簽的位置)和提及級(jí)別(標(biāo)簽位置必須完全匹配)上執(zhí)行。對(duì)于信息僅在文檔級(jí)別可用的評(píng)估集,不執(zhí)行提及級(jí)別評(píng)估。在不明確提及的情況下,如果提及至少包含“真實(shí)”物種,則該提及被視為 TP(并且,對(duì)于提及水平分析,位置正確)。我們注意到 試圖識(shí)別文件中提到的所有物種,因此報(bào)告的物種數(shù)量沒(méi)有限制。
結(jié)果
我們將 系統(tǒng)應(yīng)用于 2008 年或之前發(fā)表的近 1000 萬(wàn)篇 MEDLINE 摘要和超過(guò) 100,000 篇 PMC OA 文章(表1)。使用四個(gè) Intel Xeon 3 GHz CPU 內(nèi)核和 4 GB 內(nèi)存,MEDLINE 的文檔集標(biāo)記大約需要 5 小時(shí),PMC OA 摘要需要 2.5 小時(shí),PMC OA 需要 4 小時(shí)。(我們注意到影響處理時(shí)間的主要因素是 Java XML 文檔解析而不是實(shí)際的物種名稱標(biāo)記。)這些物種標(biāo)記實(shí)驗(yàn)遠(yuǎn)遠(yuǎn)超過(guò)了任何先前報(bào)告的規(guī)模,并代表了文本挖掘在整個(gè) PMC OA 語(yǔ)料庫(kù)中的第一個(gè)應(yīng)用。在 MEDLINE 中檢測(cè)到超過(guò) 57,000 個(gè)不同物種的超過(guò) 3000 萬(wàn)個(gè)物種標(biāo)簽,在 PMC OA 中檢測(cè)到近 19,000 個(gè)物種的超過(guò) 400 萬(wàn)個(gè)物種標(biāo)簽。 在 74% 的 MEDLINE 文章、72% 的 PMC OA 摘要和 96% 的 PMC OA 全文文章中識(shí)別出物種。從NCBI分類詞典中的物種總數(shù)來(lái)看,15%的NCBI詞典中的物種被在MEDLINE中找到,1.3%在PMC OA摘要中找到,4.9%在PMC OA全文中找到文章。MEDLINE 或 PMC OA 摘要中的物種名稱密度分別比 PMC OA 全文文章低 30 倍和 3 倍;相對(duì)于全文文檔,兩組摘要中物種提及的密度都低 11 倍。
MEDLINE 和 PubMed Central 中提到的物種的歧義
在所有 MEDLINE 和 PMC OA 中,11-14% 的物種提及是模棱兩可的。因此,物種名稱歧義的水平與基因名稱中的跨物種歧義處于相同的順序,并表明某種形式的消歧對(duì)于準(zhǔn)確的物種名稱規(guī)范化是必要的。表3顯示了 消歧步驟之前和之后的標(biāo)記文檔集的歧義級(jí)別. 歧義級(jí)別的計(jì)算方法是歧義提及的數(shù)量除以提及的總數(shù),其中當(dāng)提及映射到多個(gè)物種時(shí),會(huì)計(jì)算歧義提及。消歧方法“無(wú)”顯示任何消歧之前的值;“earlier”通過(guò)掃描文檔中較早的明確提及來(lái)消除歧義,為了比較,“whole”通過(guò)掃描整個(gè)文檔中的明確提及來(lái)消除歧義。“嚴(yán)格”消歧不考慮正確物種提及的相關(guān)概率,而“近似”表示對(duì)單個(gè)物種具有高于 99% 概率或所有物種概率之和低于 1% 的任何提及的消歧。
評(píng)估 物種名稱標(biāo)記
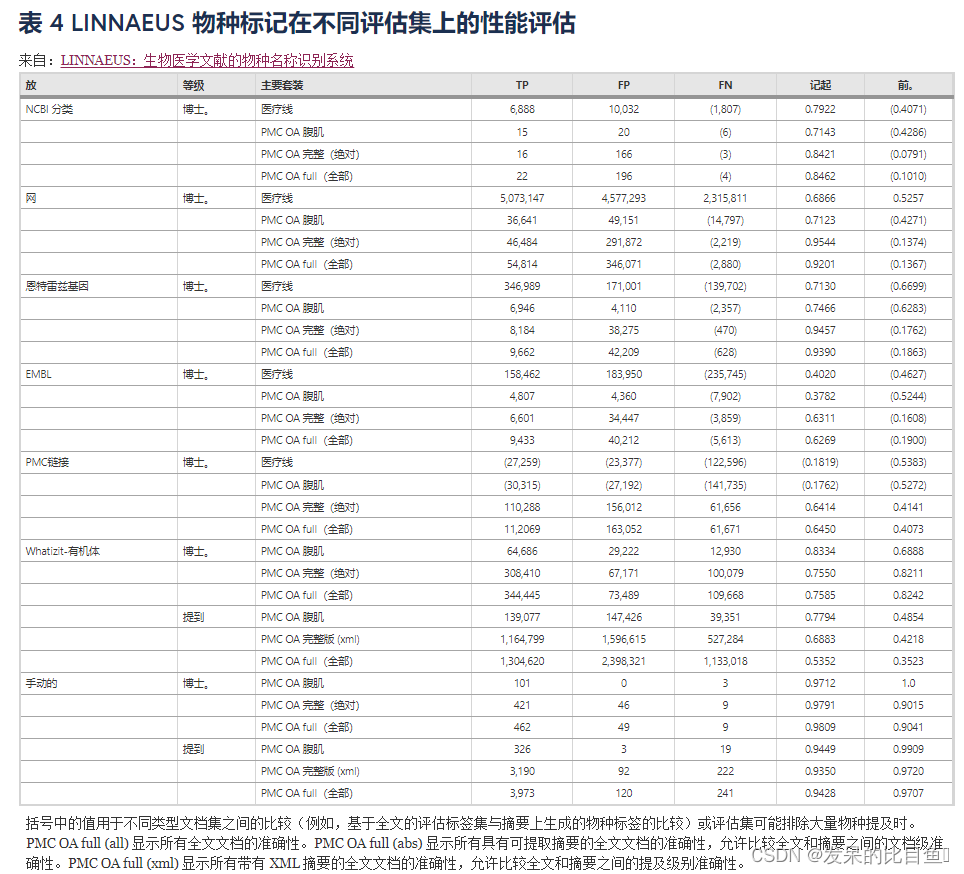
與評(píng)估集中的物種相比, 發(fā)現(xiàn)的物種提及的評(píng)估如表4所示. 對(duì)于文檔級(jí)評(píng)估集(NCBI 分類參考、MeSH 標(biāo)簽、Entrez 基因參考、EMBL 參考和 PMC 鏈接),文檔級(jí)標(biāo)簽直接與 在 MEDLINE、PMC OA 摘要或 PMC OA 中找到的標(biāo)簽進(jìn)行比較文件。對(duì)于提及級(jí)評(píng)估集( 輸出和手動(dòng)注釋集),僅在評(píng)估集和 PMC OA XML 之間直接比較標(biāo)簽,因?yàn)?PMC OA XML 是唯一與評(píng)估集在相同偏移坐標(biāo)上的文檔集(見(jiàn)方法)。對(duì)于自動(dòng)生成的集合,我們?cè)谠u(píng)估集中如何注釋物種的背景下解釋召回和精度,以提供對(duì)假陽(yáng)性和假陰性的定性分析。對(duì)于人工標(biāo)注的金標(biāo)準(zhǔn)評(píng)估集,
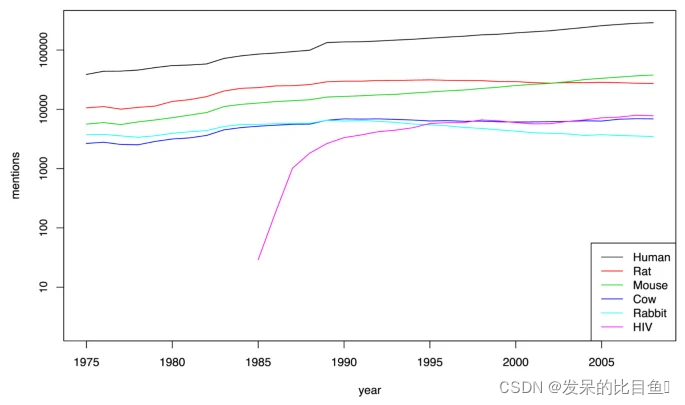
討論
物種名稱識(shí)別和規(guī)范化越來(lái)越被認(rèn)為是文本挖掘和生物信息學(xué)中的一個(gè)重要主題,不僅因?yàn)樗梢詾樽罱K用戶提供直接優(yōu)勢(shì),而且還可以指導(dǎo)其他軟件系統(tǒng)。雖然之前已經(jīng)報(bào)道了許多執(zhí)行物種名稱識(shí)別和/或科學(xué)名稱和同義詞標(biāo)準(zhǔn)化的工具,這里介紹的工作以多種獨(dú)特的方式為該領(lǐng)域做出了貢獻(xiàn)。其中包括強(qiáng)大的、開(kāi)源的、獨(dú)立的應(yīng)用程序的可用性(其他工具要么不公開(kāi)提供,只能作為 Web 服務(wù)提供,要么不能識(shí)別常用名稱)、物種標(biāo)記的規(guī)模(所有 MEDLINE 和 PMC OA 直到2008)、評(píng)估的深度和嚴(yán)謹(jǐn)性(其他工具不針對(duì)規(guī)范化的數(shù)據(jù)庫(kù)標(biāo)識(shí)符進(jìn)行評(píng)估,或者僅限于少量文檔樣本)和準(zhǔn)確性(與其他可用工具相比, 表現(xiàn)出更好的性能,主要是由于更好地處理含糊不清的提及和包含其他同義詞)。此外,我們提供第一個(gè)開(kāi)放訪問(wèn),
評(píng)估物種名稱識(shí)別軟件需要人工注釋的金標(biāo)準(zhǔn)
任何生物信息學(xué)應(yīng)用程序的相對(duì)性能僅與與之比較的評(píng)估集一樣好。在物種名稱識(shí)別軟件的情況下,在當(dāng)前工作之前,沒(méi)有開(kāi)放訪問(wèn)的生物醫(yī)學(xué)文本中物種名稱注釋的手動(dòng)注釋數(shù)據(jù)集作為評(píng)估的黃金標(biāo)準(zhǔn)。在這個(gè)項(xiàng)目中,我們研究了四種不同的自動(dòng)生成的評(píng)估集(NCBI 分類引文、MeSH 標(biāo)簽、Entrez 基因參考、EMBL 引文),這些評(píng)估集基于策展的文檔-物種對(duì)。我們還根據(jù)使用文本挖掘軟件(PMC 和 )預(yù)測(cè)的文檔物種對(duì)研究了兩個(gè)不同的自動(dòng)生成的評(píng)估集。盡管當(dāng)文檔集和評(píng)估集屬于同一類型時(shí),可以解釋 的召回(例如全文),由于在任何這些評(píng)估集中對(duì)物種提及的不完整或不完善的注釋,我們的系統(tǒng)的精度無(wú)法準(zhǔn)確評(píng)估。我們得出結(jié)論,從“次要”來(lái)源(例如文檔基因(例如Entrez 基因)或文檔序列(例如EMBL)映射)自動(dòng)推斷出的文檔-物種映射評(píng)估集在評(píng)估物種名稱識(shí)別軟件中的價(jià)值有限。
由于自動(dòng)生成的評(píng)估集的固有局限性(包括物種名稱的不完整注釋或不正確的消歧),因此創(chuàng)建了手動(dòng)注釋的評(píng)估語(yǔ)料庫(kù)。對(duì)手動(dòng)注釋評(píng)估語(yǔ)料庫(kù)的評(píng)估顯示, 的性能非常好,在提及級(jí)別上具有 94.3% 的召回率和 97.1% 的準(zhǔn)確率,在文檔級(jí)別上具有 98.1% 的召回率和 90.4% 的準(zhǔn)確率。沒(méi)有一個(gè)自動(dòng)生成的評(píng)估集能接近揭示使用 進(jìn)行物種名稱識(shí)別的這種精度水平。這些結(jié)果強(qiáng)調(diào)了我們手動(dòng)注釋的黃金標(biāo)準(zhǔn)評(píng)估集的重要性,并建議在自動(dòng)生成的評(píng)估集上評(píng)估其他系統(tǒng)可能低估了系統(tǒng)精度。擁有高質(zhì)量評(píng)估集的一個(gè)有趣觀察是,召回率高于文檔級(jí)別的準(zhǔn)確率,而準(zhǔn)確率高于提及級(jí)別的召回率。造成這種情況的一個(gè)原因是,當(dāng)作者使用非標(biāo)準(zhǔn)或拼寫(xiě)錯(cuò)誤的名稱時(shí),他們通常會(huì)在整個(gè)文檔中多次使用這些名稱,導(dǎo)致在提及級(jí)別上出現(xiàn)多個(gè)誤報(bào),但僅在文檔級(jí)別上出現(xiàn)一次。相反,誤報(bào)在文檔中更分散,導(dǎo)致提及和文檔級(jí)別評(píng)估的誤報(bào)計(jì)數(shù)差異很小。
提高全文文章中物種名稱識(shí)別的準(zhǔn)確性
目前絕大多數(shù)文本挖掘研究都是針對(duì)生物醫(yī)學(xué)文章的摘要進(jìn)行的,因?yàn)樗鼈冊(cè)?PubMed 中免費(fèi)提供,分析所需的計(jì)算資源較少,并且被認(rèn)為包含最高密度的信息。然而,越來(lái)越多的證據(jù)表明,全文文章的信息檢索效果更好,因?yàn)樯镝t(yī)學(xué)術(shù)語(yǔ)的覆蓋率高于摘要。我們的物種名稱識(shí)別結(jié)果支持這一結(jié)論,對(duì)于大多數(shù)測(cè)試的評(píng)估集,全文文章的物種名稱召回率高于摘要(表4) 并且?guī)缀跛?(96%) 全文文章都被標(biāo)記為至少一個(gè)物種名稱。對(duì)全文文章進(jìn)行術(shù)語(yǔ)識(shí)別的好處在物種名稱的情況下可能特別有用,因?yàn)榕c疾病、基因或化學(xué)品和藥物的術(shù)語(yǔ)相比,生物術(shù)語(yǔ)在生物醫(yī)學(xué)文檔的不同部分中的分布似乎更加統(tǒng)一。
我們的結(jié)果還清楚地表明,通過(guò)搜索明確提及來(lái)消除物種提及的歧義在全文文章中比在摘要中更成功。因此,正如之前發(fā)現(xiàn)的基因名稱,全文覆蓋率的增加對(duì)物種名稱消歧有額外的好處,因?yàn)樵谔幚砣奈恼聲r(shí),消歧算法可以獲得更多信息。有趣的是,我們發(fā)現(xiàn)無(wú)論是在文本的前面還是在整個(gè)文本中掃描明確提及,歧義的程度都會(huì)下降,這可能是因?yàn)槲恼碌牟牧虾头椒ú糠滞ǔN挥谡撐牡哪┪病T谒阉髅鞔_提及后,我們發(fā)現(xiàn)生物醫(yī)學(xué)文本中物種名稱的歧義水平很低(3-5%),如果可以容忍少量錯(cuò)誤,可以使用概率方法進(jìn)一步降低(1-3%)。
結(jié)論
我們開(kāi)發(fā)并評(píng)估了一個(gè)強(qiáng)大的開(kāi)源軟件系統(tǒng) ,它可以快速準(zhǔn)確地識(shí)別生物醫(yī)學(xué)文件中的物種名稱,并將它們規(guī)范化為 NCBI 分類中的標(biāo)識(shí)符。 系統(tǒng)的低歧義性、高召回率和高精度使其非常適合生物醫(yī)學(xué)文本中的自動(dòng)物種名稱識(shí)別。生物醫(yī)學(xué)領(lǐng)域的 物種識(shí)別可以通過(guò)包含細(xì)胞系名稱來(lái)增強(qiáng) [ 67 ],這些名稱通常充當(dāng)產(chǎn)生它們的物種的生物代理。 也可能在其他問(wèn)題領(lǐng)域表現(xiàn)良好,例如生態(tài)學(xué)和分類學(xué)文獻(xiàn),前提是提供高質(zhì)量的物種名稱詞典(例如 [ 68]),盡管這仍然是未來(lái)研究的開(kāi)放領(lǐng)域。進(jìn)一步開(kāi)發(fā) 以在生物醫(yī)學(xué)文獻(xiàn)之外更廣泛地應(yīng)用可能需要與其他方法集成,例如基于規(guī)則的物種名稱識(shí)別系統(tǒng)(例如 ),我們目前的目標(biāo)是在未來(lái)提供此類方法的實(shí)現(xiàn),以便能夠使用 提供的文件處理方法。 的可用性現(xiàn)在為在文本中使用物種名稱的下游應(yīng)用程序提供了機(jī)會(huì),包括將物種名稱集成到更大的生物信息學(xué)管道中,生物醫(yī)學(xué)文本中物種名稱的語(yǔ)義標(biāo)記,以及跨物種名稱使用趨勢(shì)的數(shù)據(jù)挖掘文件和時(shí)間。
*請(qǐng)認(rèn)真填寫(xiě)需求信息,我們會(huì)在24小時(shí)內(nèi)與您取得聯(lián)系。
