整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
“非結構化數據在大多數情況下需要實現結構化才便于后續的數據產品化。”
結構化數據,非結構化數據這兩個術語伴隨數據要素的全生命周期,特別是在前期治理階段,是大家經常會打交道的兩個術語,如果還有朋友對這個兩個術語的區別不是很清楚,今天的內容就值得看一看。
01 定義
——————————————————
我們談到數據,第一反應就會想到數據庫。其實數據庫中存儲的,絕大部分就是 結構化數據。
就像檔案館里的文件管理方式一樣,要分門別類放在該放的位置,然后還要建立索引以方便查找。

接觸過數據庫設計的朋友都知道,要向數據庫中存儲數據,首先要做的就是數據庫的結構設計,要定義庫,表,字段,以及字段的類型和長度,才能進行下一步的數據操作。
而非結構化數據的定義,正好和數據庫中的結構化數據相反,它是“數據結構不規則或不完整,沒有預定義的數據模型,不方便用數據庫二維邏輯表來表現的數據。”,常見的包括辦公文檔、文本、圖像和音頻/視頻信息等等,這些數據的特征就是量大,只能作為一個整體來使用。
比如我們日常工作用遇到的如下一些類型:
這些數據在使用過程中,如果要搜索內容,就只能用工具比如WORD打開以后,對全文進行檢索。而不是像數據庫,就像我們的日常OA里邊一樣,可以指定某個條件,還可以指定判斷方式是等于大于小于,然后設定值就可以查詢,這就是使用中結構化和非結構化的區別。
我們用表格來對比一下二者的關系和區別
結構化數據
非結構化數據
適合預定義數據模型或架構的數據。
沒有底層模型來辨別屬性的數據。
基本示例
Excel 表。
視頻文件的集合。
最適用于
離散、簡短、非連續數字和文本值的關聯集合。
屬性更改或未知的關聯數據、對象或文件集合。
存儲類型
關系數據庫、圖形數據庫、空間數據庫、OLAP 多維數據集等。
文件系統、DAM 系統、CMS、版本控制系統等。
最大的優勢
更易于組織、清理、搜索和分析。
可以分析無法輕松形成結構化數據的數據。
最嚴峻的挑戰
所有數據均必須符合規定的數據模型。
可能很難分析。
主要分析技術
SQL 查詢。
復雜。
此外,還有一個定義,就是半結構化數據,顧名思義就是介于二者之間,有點結構,但是又不像數據庫那么嚴格。比如下邊百度百科對非結構化數據介紹的頁面。

這里邊,就會有中文名,外文名,特點,這樣的標記,是不是很像數據庫的字段?但是又沒有嚴格的按照字段來存儲和使用,而是統統放在了文本里。但是對文本處理的時候,如果我預知了有這些字段,我就可以更加快捷高效的處理這些文本,同時存儲的時候也不用設計數據庫那么麻煩,這就是半結構化數據的優勢,二者兼備。
02非結構化數據的特點和價值
——————————————————
結構化數據的價值我們就不多說了,從1970年IBM Codd提出關系型數據庫的理論到現在,沒有數據庫,可以認為就不會有我們現在所有信息化系統。
當然,除了關系型數據庫,還有其他的數據庫理論和產品,但是關系型,也就是我們現在使用最多的比如IBM DB2,Oracle,開源的Mysql/MariaDB/,都是關系型數據庫的實現。
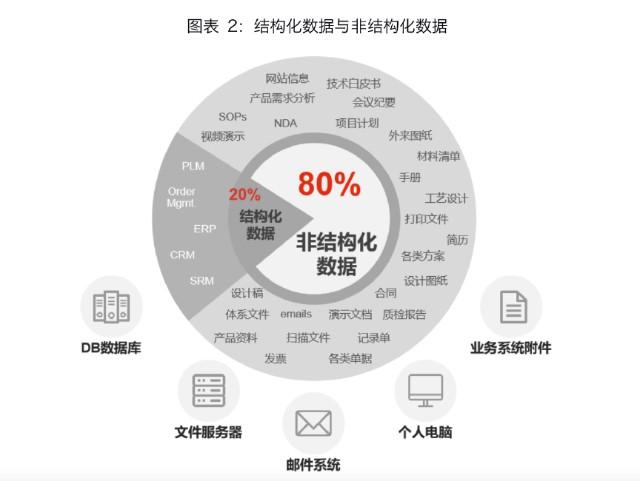
而隨著互聯網的發展,大量的非結構化數據被生產和傳播,首先是第一代互聯網的HTML文本,他們構成了我們的網頁內容。后來隨著網速的提升,特別是從3G以后,大量的圖片和視頻開始在互聯網傳播,這些形成了非結構化數據的主體。
而且很明顯的,非結構化數據的所占用的存儲空間,會遠遠大于結構化數據,實際上現在大體是28開。
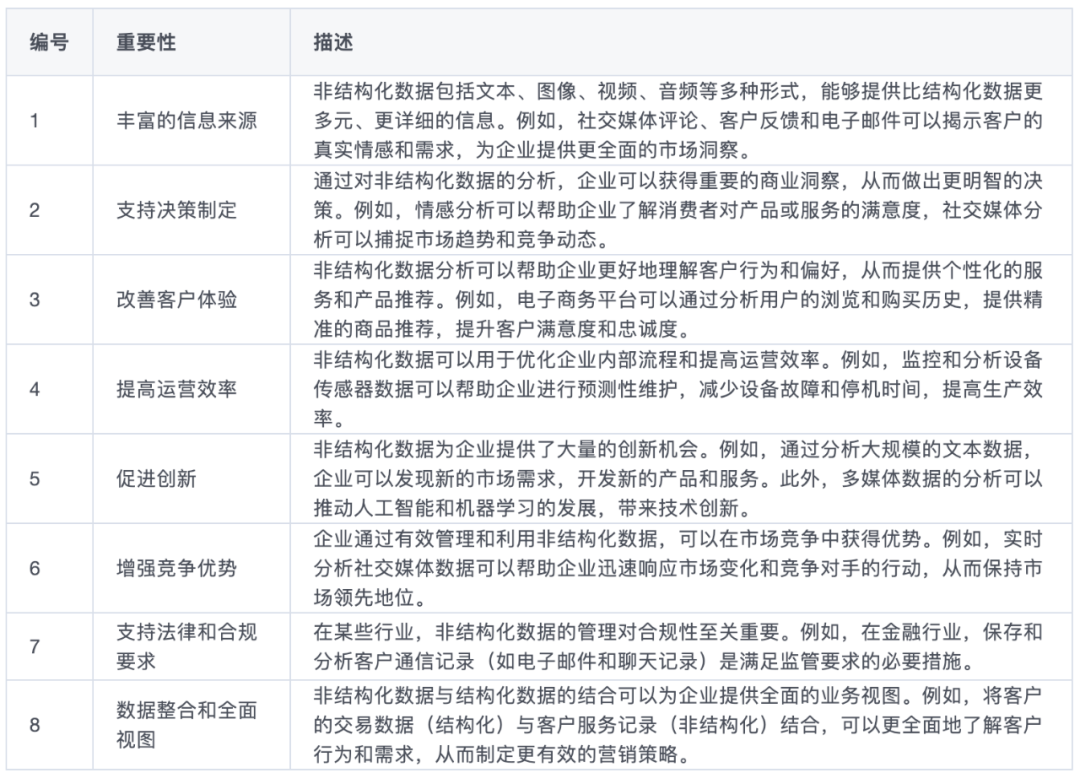
但是,非結構化數據自然也有其優勢,我們借用傅一平博士的總結:
特別是在豐富信息來源,提供更豐富的呈現方式,促進創新方面都有優勢。
03非結構化治理的挑戰
——————————————————
非結構化數據因其自身特點而具備上述優勢的同時,也帶來了治理的難度。舉個簡單的例子,大家對手機上的照片和視頻是不是都覺得頭疼?對企業來講,更加巨量的數據帶來了治理的挑戰。
1、數據種類繁雜,形式多樣
由于企業日常經營管理和業務管理的需要,建立了功能各異的應用系統或信息化管理平臺,而這些管理系統和平臺中生成了形式多樣的非結構化文檔數據,用以支撐企業的各類管理工作。
除此之外,還有大量與管理相關的非結構化文檔數據散存在員工個人工作電腦中。這些數據種類繁雜,有的來源于外部,有的是經過內部整理編研形成的,有的則是完全產生于內部;涵蓋了不同格式、不同存儲載體、不同管理階段的非結構化文檔數據。
企業擁有形式多樣的存儲設備,包括個人工作電腦以及信息化管理平臺中管理的設備,且歸屬于不同的專業領域,業務活動中產生的非結構化文檔數據除了常見的與辦公活動相關的非結構化文檔數據外,還包括了如照片、視頻、設計圖紙等多種形式。目前,這些不同種類的非結構化文檔數據基本處于分散狀態,很難進行有效的關聯和整合。
2、非結構化文檔數據管理功能不全
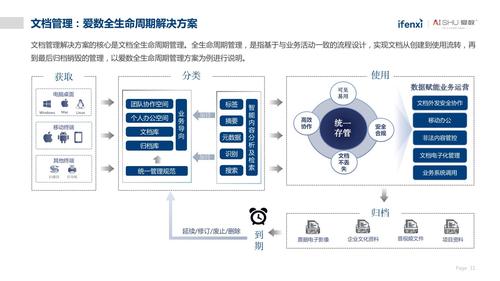
企業一些信息系統(如OA系統、ERP系統等)中文檔多以表單(如辦文單)的形式進行流轉,需要辦理的文檔通常作為表單的附件,其中既有word或pdf等格式的文本文檔,也有多種格式的圖片、音視頻文件等。這些非結構化文檔往往只能借助其所依附的表單信息或者簡單的文件標題等元數據加以檢索和利用,檢全率低,開發利用不足,難以開展深度的數據挖掘與分析。
3、存在過多的“賬外”非結構化文檔數據,缺少統一管控
由于企業的歸檔制度不夠完善,集團制訂的歸檔范圍未將一些應歸檔但無法通過系統流轉的文檔納入其中,部門相當一部分非結構化文檔數據仍保存在個人電腦之中,沒有統一的管理和控制,難以進行檢索和共享利用,導致企業文檔數據資產存在著流失的風險。
4、相關制度體系不健全、管理缺位
企業現有的文檔管理制度并不是建立在徹底的數據清理基礎之上,因此,對于企業中生成哪些非結構化文檔,哪些需要歸檔,如何進行歸檔?如何進行管理和利用等問題,現有制度中均缺少系統、細致、可操作的規定和描述。
而且,非結構化文檔數據缺少必要的分類及元數據項。尤其是文檔生命周期流程,即從文檔生成、流轉、辦結到歸檔、保存、利用的全過程,并沒有非常清晰和規范的管理流程和要求。
04非結構化數據如何治理
——————————————————
非結構化數據的治理相比結構化數據,更加復雜。
非結構化數據都散落在各個文件系統中,甚至是以原始物理文件存儲的,盤點的時候就不能像結構化數據一樣,直接連接數據庫讀元數據進行盤點。
我們這里也只能圍繞如何啟動治理提出建議,而盤點之后的步驟,更多就要依賴企業的治理軟件進行開展了。
按照DAMA的規范,首先要構建元數據,非結構化數據的盤點的核心毫無疑問也是元數據。而且這個環節完全無法依賴系統,是需要人工結合業務實際情況開展的。
元數據的建立和盤點大致流程如下:
1、梳理業務流程;
2、整理業務輸入;
3、整理業務輸出;
4、整理非結構化數據元數據,并形成標準;
5、補充業務信息(包括編碼、業務分類、業務含義、摘要、標簽等);
6、編制成冊
最終的成果就是類似這樣的一套表格,包括文檔名稱、編號、業務所需各類信息。
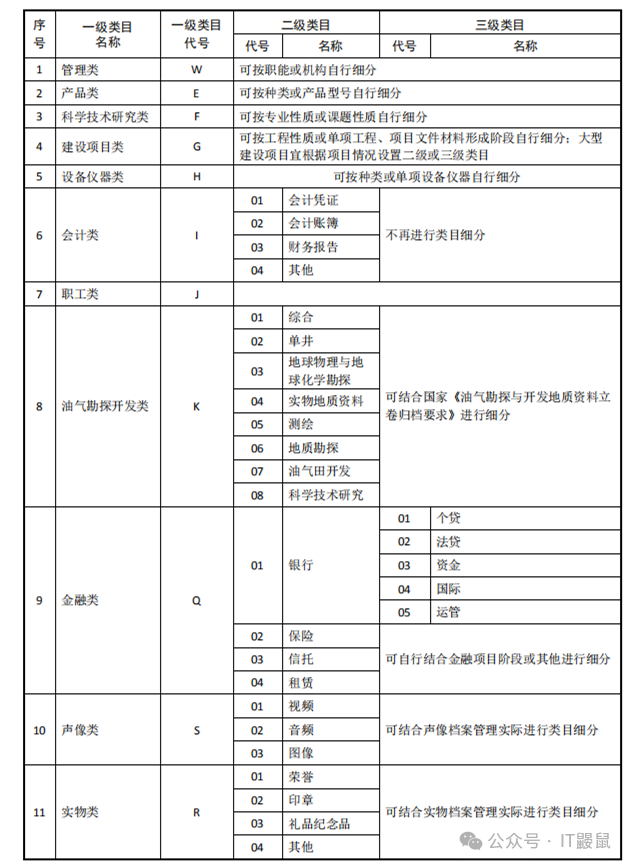
大家是不是有點特殊的感覺,這不是結構化數據嗎?
沒錯,非結構化數據的管理,其實很大程度上就是要依賴于提取其中的結構化數據,才可以進行有效的管理。比如照片中的時間,以及GPS位置信息,視頻的長度信息和封面的文字等等,否則,管理就無從談起。
回到企業業務相關場景,有了上邊一套來自業務實踐的表格,我們就可以啟動相關的系統化建設,通過對數據庫的設計,開始把非結構化數據管理起來了。
后邊我們可以就這里的兩個細節,即非結構化數據中結構化信息的提取,以及如何管理再去深入探討。今天先到這里。
—————————————————————————
數據資產化,鼴鼠哥與你一起。

歡迎大家公眾號后臺留言,或者后臺回復“進群”,進群一起聊。
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
