整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
計算機和軟件專業的同學在本科期間都有一門必修課:國內大多數叫《數據結構》,國外大多叫《算法導論》,非常重要。分為兩部分:數據結構——array、list、stack、queue、tree、set、graph等,和算法——增刪改查、排序等等。
這是狹義上的數據結構和算法。實際軟件開發中,只要涉及到復雜的功能時,往往會涉及書本之外的數據結構和算法的問題。對于大型軟件工程來說,尤其是游戲引擎這種對性能要求近乎苛刻的系統,算法尤為重要。
但是,我們在大學里學習《數據結構》這門課時,并不知道的一點是,這些數據結構和算法都是在計算機的“鴻蒙時代”設計出來的,計算和數據讀取的性能接近。但是如果運行在當今的硬件上,可能使用map不見得比無腦遍歷連續數組的方式更快,甚至同樣的算法在不同的硬件架構下也會得出截然相反的結果。忽視了硬件特性的數據結構和算法,高性能就是鏡中花,水中月。遺憾的是大學里老師不會告訴我們這些,以至于工作了很多年的程序員,甚至是很多引擎程序員都不知道,依然生搬硬套教科書上的做法,難免貽笑大方。
寒霜引擎做過一件“毀三觀”的事:不用四叉樹、八叉樹、BSP、BVH、Portal等來管理場景,而是無腦遍歷所有場景實體,竟然更快。見《Culling The 》。
那么這是為什么呢?其實這是近代計算機硬件的發展趨勢導致的。我們先來看一下近些年來硬件的發展軌跡,見下圖(不要糾結現在馬上就2021年了,而圖中的數據只到2010年)。圖中顯示了計算性能大幅提升,而帶寬卻發展緩慢。
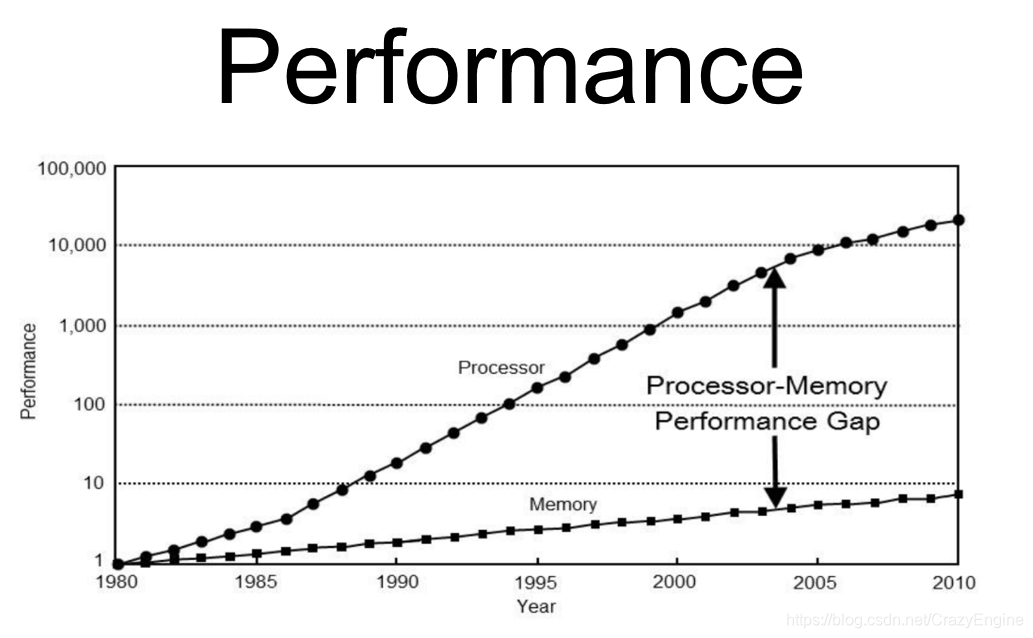
為了提升性能,當前PC上的CPU都是金字塔式的三級cache:越靠近CPU,cache大小越小,速度越高。執行命令訪問數據時,先從cache line開始查找,沒有的話就依次向遠離CPU的方向訪問各級cache,一直到主存儲器,甚至是去磁盤或者外部存儲設備上訪問數據。這樣,如果數據組織的跟算法的訪問順序很接近,那么就能大幅減少Cache miss,從而大幅提升性能。那可能有人要問,干嘛不給CPU一大塊速度非常高的cache呢?很簡單,就是成本太高了。

所以,如果你寫的代碼性能低,可能往往不是你的指令太多,而是數據排布的不合理,造成了大量的cache miss。
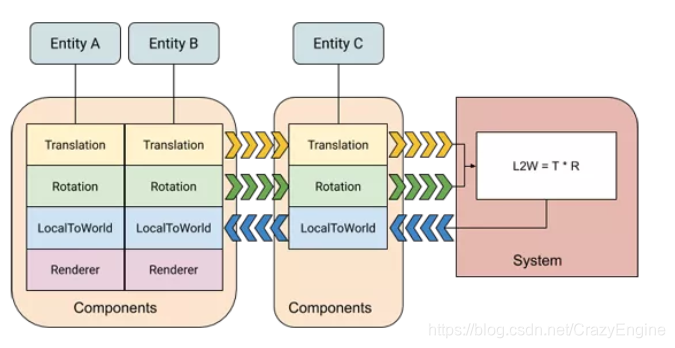
針對這種硬件現狀,就誕生了一種新的程序設計思想——面向數據編程(Data- design),簡稱DOD。傳統的面向對象設計是以功能為核心的,而DOD是以數據處理為核心的(程序的根本目的不就是處理數據嗎)。核心思想就是將需要處理的相關數據都緊密排布在物理存儲器上,一次性處理一組對象的某個操作,而不是隨意訪問分散在物理內存上的各種數據。另外需要注意的是,程序本身也是數據,執行前也需要加載到CPU去執行,一次性處理所有的數據就不存在反復加載程序了。DOD的數據組織形式最典型的一種就是將AOS(Array of )改成SOA( of Arrays),分別見下圖(出自)。



DOD也不是什么新技術了,Ogre 2.0多年前就開始研發了,計劃從面向對象改成面向數據設計,見《OGRE.2.0.pdf》。2013-2015年在自研《盤古引擎》時也開始使用包括DOD這樣的cache友好的設計思想,下面羅列這期間遇到過的一些相關案例。
數據壓縮是最常見的一種cache友好的方案。例如,我們紋理壓縮、頂點屬性壓縮,甚至是延遲著色里的GBuffer也能瘋狂壓縮(曾經將GBuffer壓縮到了3張RT)。
內存池和對象池是為了解決內存碎片,但是也利于性能提升。
將Ogre里的八叉樹改成Cache友好的四叉樹,性能提升很多。
使用面向數據設計去重構粒子系統,大幅減少cache miss。
SSAO采樣數量一定的情況下,隨著采樣核的增大,耗時也會增大,為啥?就是因為GPU上的cache大小也是有限的,采樣范圍大了就增加了cache miss。還有,渲染SSAO時用了一個4x4的隨機紋理,在屏幕上反復平鋪以增加采樣方向的隨機性,也實踐了數據訪問的連續性。下圖分別為隨機紋理、中間結果和最終過濾的結果。



模型里的頂點在編輯器里需要排序,以有效利用VS處理時的cache。
Stl庫里的很多容器()的第二個模板參數默認都是內置的模板類 class 。一般來說,內置的分配器就足夠了。但是對于3D實時引擎這種對性能要求近乎苛刻的系統,自己設計一個就可以根據實際的應用場景來合理排布容器元素。

曾幫一家公司優化過一個算法,里面需要遍歷一個二維數組,修改下訪問的主序就能得到截然不同的性能。
之前做分布式紋理壓縮時深入研究過pvr這種外部壓縮格式,內部壓縮格式有PVRTC2和PVRTC4。發現它們的紋素排列方式很詭異,并不是像其它壓縮格式那樣簡單地從從上到下、從左到右,而是之字形排布的。推斷為的也是cache友好,須知GPU里的顯存也是有cache的,我們shader里進行一次采樣,其實硬件就是將一大塊都從顯存里傳輸到cache里了。除了CPU上有“cache友好”這一說法,GPU上也是有的。

最近兩年Unity也搞出了ECS,其實就是新瓶裝舊酒,底層依然是DOD的設計思想。當然不可否認的是Unity一貫的優勢——易用性做的真的很好。盡管各種引擎內部都支持DOD的設計,但是能將這個技術暴露出給用戶使用的,獨此一家。
所以說數據的組織形式比算法更重要:算法是由需求決定的,數據要按照算法去排布。
當然,DOD也有缺點,會破壞封裝性,增加了維護成本。那么怎么來決定是用OOD還是DOD呢?我的結論是,將你代碼里的1%-10%的代碼熱點使用DOD,其它地方使用OOD。“將性能優化到極致”是我的口頭禪,但是也不會不明白“過猶不及”的道理。世界上絕大部分選擇本就是妥協的結果。
那么回到原來的問題,大學學習《數據結構和算法》就沒有用處了?絕不是的。首先是通過這門課來深入理解軟件運行的原理。另外,還能鍛煉邏輯思維能力。當然還有很多都可以鍛煉邏輯思維能力,比如那個輟學搞寫作的韓寒曾說過,靠學習數學來練習邏輯思維能力就是扯淡,他認為寫作更能鍛煉這個能力。
那么學習《數據結構和算法》還有什么額外的用處呢?肯定也是有的。保不準哪一天等你已經工作了十幾年以后,還有極個別公司面試時會拿這個來難為你,這時你就不用再消耗寶貴的時間去翻書了。
最近很忙,隨便寫點吧,寫到哪算哪。引用的很多案例都是很多年前的,難免記憶出現錯位,也懶得去查筆記驗證了,出現錯誤請求讀者斧正。另外很多地方跳躍性較強,也難免燈下黑。老引擎程序員可能都碰到過類似問題,看后會心一笑。新入行的看懵的話也不負責解釋,以后工作中慢慢去品吧。
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
